[译介] 纹理压缩技术 #
本文翻译自一篇由 T. Paltashev 和 I. Perminov 撰写的论文,其英文版本链接如下:
概述 #
本篇文章,会从压缩比和图像质量角度出发,分别在技术层面和现代硬件 (如:PC,手机和平板) 层面对不同的纹理压缩技术进行深入分析和比较。首先我们会分析最早广泛使用的 S3TC (BC1-BC3) 系列。随后会逐个分析一些通过增加灵活性和使用块分割技术而大大改进图像质量的新系列: BC4, BC5, BC6H 以及 BC7。接着分析由爱立信开发的面向移动端的 ETC(PACKMAN, ETC1 ( iPACKMAN ) , ETC2/EAC) 和 Imagination Technologies 发明的 PVRTC。最后会分析由 AMD 与 ARM 协同开发的 ASTC 技术。我们也会详细讨论 ASTC 所使用的 BISE 编码技术和其他特性。
关键词:computer graphics, texture compression, texture decompression, S3TC, DXT, BCn, BC6H, BC7, ETC, ETC2, EAC, PVRTC, PVRTC2, ASTC.
前言 #
如果没有不同的纹理,3D 计算机图形学恐怕是不可想象的。在不增加几何复杂度的前提下,纹理技术能够大幅提升图形质量。简单的纹理是映射在 3D 表面上的 2D 图像。纹理中的每一个像素又称为纹素 (纹理的基本单位) 。通常除了颜色信息,纹理还能够存储高度信息、法线方向以及镜面系数等 (见图1) 。现代 3D 应用和游戏会占用大量的内存,而其中一半以上都被纹理所占用,因此对内存大小和带宽有很高的需求。各种纹理压缩技术应运而生,以减少对内存和带宽的压力。基于这种情况,材质通常都是以压缩状态存储在内存中并传输至 GPU。解压过程只发生在 GPU 上,通常位于 L1 和 L2 cache 之间。这样的话,不仅减少了内存占用,也同时节省了带宽。压缩同时也能够节省功耗,因为 GPU 核心同显存之间的数据交换也是会产生功耗的,而这一点对于移动设备尤为重要。
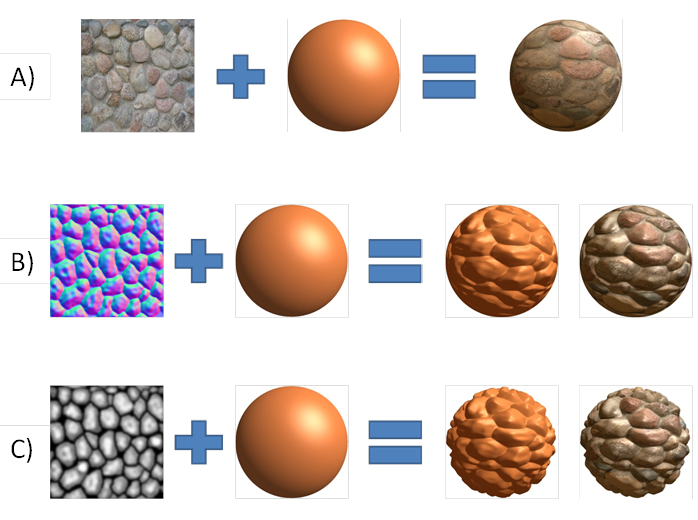
[图1]: 不同类型的纹理映射示例。A - 漫反射贴图; B - 法线贴图 C - 位移 (高度) 贴图
纹理压缩的特性 #
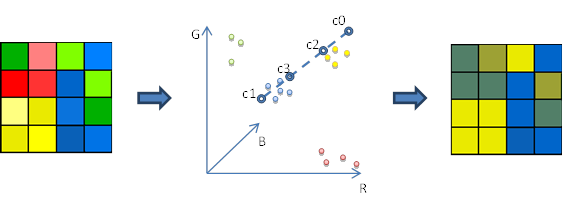
绝大多数情况下,纹理表现为一张 2D 图片。但标准的压缩算法 ( RLE, LZW, Deflate) 以及常用的图片压缩格式 ( JPEG, PNG TIFF) 并不适用于纹理压缩。主要原因是上述算法不满足随机访问。因此很难在不解压整张纹理的前提下直接访问某个特定的纹素。纹理访问的模式高度随机:只有在渲染时被用到的部分才需要访问到,且无法提前预知其顺序。而且在场景中相邻的像素在纹理中不一定是相邻的 (见图2) 。因此图形子系统的性能高度依赖于纹理访问的效率。随机访问决定了各种纹理压缩格式的主要特点。
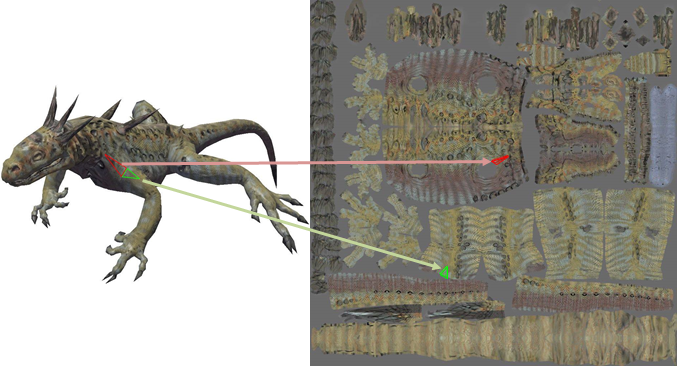
[图2]: 纹理布局示例。(纹理和3D网格来源:Microsoft DirectX 9 SDK)
多数纹理压缩策略会将整张纹理划分为固定大小的块 (Block),又称为瓦片 ( Tile),每个瓦片被单独压缩。但也有一些特例,如 PVRTC。评估一个纹理压缩方案,需要考虑以下因素:
- 随机访问。GPU 需要能够随机有效地访问任意纹素。因此几乎所有的压缩器都拥有固定的压缩比。 这也就意味着有损压缩。当然非固定压缩比也是能够胜任随机访问的需求的。例如,Inada和McCool在(2)中提出了无损的可变速率方案,通过修改纹理缓存结构来实现高性能。
- 高解压速度。 贴图访问速度也是会影响图形子系统性能的关键因素,由此引出下述两个因素:
- 解码器的低成本硬件实现。解压算法应当相对简单,所以很少用到小波变换 (wavelet) 以及离散余弦变换 (DCT- disrete cosine transform) 。
- 无间接和连锁内存访问。理想情况下,只需读取一次内存就能获取解码一个小区域的纹理所需的全部信息。而为了获得过滤的纹理,只进行最低限度的额外读取。任何额外的内存访问 (如读取调色板或其他表) 都增加了整体延迟。由于降低了局部性,间接访问还会拉低缓存效率。
- 高压缩比。这是在进行纹理读取时,决定带宽占用的主要因素。压缩比通常用比特率或每像素平均比特数 ( bpp - byte per pixel 译注:原文为 byte per texel) 来表示。典型的 bpp 的值为从 2bpp 到 8bpp。
- 图片会被分割成小块,通常为 4x4 纹素。块太小的话会比较难压缩,而太大的话又会影响到 cache 命中。另外,为了减少延迟和简化硬件实现,压缩块的大小最好小于内存总线的宽度。如果一个压缩块所占的位数与总线宽度相同,就可以避免流水线停顿(3)。现代图形处理器的内存总线通常从 64 位到 512 位。由于严格的硬件和功率预算,移动设备的纹理压缩方案利用非常高的压缩比 (2bpp) 或更小的块来适应内存总线宽度。
- 解压后的纹理有可接受的视觉质量。压缩器引入的失真当然是越小越好。
流式纹理压缩 #
在这篇文章中,我们将只详细讨论提供随机访问并有硬件支持的格式。但是这里仍旧需要提及一下流式纹理压缩。这种技术用于将贴图快速从硬盘或网络加载到显存中。对于图像数据达到千兆字节量级的现代应用来说,这的确是个问题。
首要的目标是降低数据大小。在没有随机访问的要求时,便可以实现非常高的压缩比和 (或) 无损压缩。当纹理加载进内存之后,就可以用可编程着色器解压它。其输出可能是未压缩的格式,也可能是硬件支持的压缩格式。也可能通过以下方式优化内存管理:在显存中保存高度压缩的完整纹理集,并为当前场景的纹理子集使用一个对 GPU 有好的格式。
相较于常用的压缩手段 (RLE, LSW, Deflate),这种特殊的压缩方式提供了更好的压缩比。对于游戏主机,也能够让开发者在一张光盘里存放更多内容。
例如,IdTech5 引擎 (4) 使用的虚拟纹理技术可以将类似 JPEG 格式的纹理加载并实时转码至 DXT。不过这两种格式都会引入压缩伪影。
说到这里,就需要提及一下其他出版物中, Olano 等人 (5) 提出的与 mip-map 紧密耦合的有损和无损压缩方案,以及 Ström 等人 (6) 提出的针对 ETC 格式再进行无损压缩的方案。
速度与质量 #
虽然原始图像与重建图像之间的区别很大程度取决于压缩格式,压缩算法在其中也起着重要作用。显然,基于穷举搜索的算法能够以性能为代价获得最好的质量。对于大多数算法来说,以合理的速度获得良好的质量仍是一项艰巨的任务。如上所述,在比较纹理压缩的质量时,必须详细说明如何进行压缩以及使用哪种算法。
解压算法同样能够影响图像质量。例如,在 GeForce/GeForce2 的芯片中硬件实现的 DXT1 解码器,所有内部色彩指令均工作在 16 位模式下,而不会转换到 24 位模式 (7) 。因此会在解压时引入额外的伪影 (见图3) 。

[图3]: 压缩的伪影。A - 未压缩,B - S3 Savage2000 上的 DXT1,C - NVidia GeForce 256上的 DXT1 (来源:iXBT (7) )
传统的实时 3D 图形会采用离线压缩器对纹理进行预压缩。而现代的渲染引擎越来越多使用大量动态生成的数据,如:用于模拟反射的环境贴图、延迟着色中使用的 G-Buffer 等。这就使得实时纹理压缩 (纹理会在每一帧都进行压缩) 有了用武之地。实时压缩也会用于低延迟高分辨率的视频流,如 UltraGrid (8) (9)。
虽然针对某些格式的快速压缩算法早已存在 (10) (11) (12),但由于硬件限制,针对动态生成数据的压缩仍需要新的方法。
例如,像素着色器无法访问相邻的像素。为了避免可能的像素重叠,因此一个瓦片的结果只有在整帧渲染结束之后才能访问。 解决这些问题的方法之一是使用 tile-based GPU 架构。尽管纹理在被送入显存后也可以被压缩,但当前的 3D API (D3D 11.2, OpenGL 4.4) 所引入的数据复制开销大大削弱了这种方法的效率(13)。
在本文中,我们将会更详细讨论一些知名的纹理压缩格式:
- S3TC 系列,应用于个人电脑
- 针对移动端设计的 ETC 和 PVRTC 系列
- 以及 ASTC,适用于全平台的新格式
早期的重要工作 #
最简情况下,一个像素的编码可以直接用一个数字 (通常为 4 位或 8 位 ) 表示,对应调色板上的一个索引。这个技术在早期广泛应用于视频适配器或游戏主机上,用以降低视频帧缓冲器的大小和带宽。然而,调色板并不太适用于纹理压缩,原因如下:
- 低压缩比 (比较典型的为 8bpp)
- 受限于调色板的色彩上限,质量差 (8bpp 时只有 256 色)
- 两次内存访问 (一次纹素,一次调色板) 占用了更高的带宽,同时也增大了延迟。尽管调色板的内存可以作为一个专用的 RAM 来实现,但每次访问新的纹理时,仍需重写调色板。
调色板压缩是矢量量化 ( VQ - Vector Quantization) 的一个特例,矢量是单个像素。世嘉 Dreamcast 游戏机使用了一种更为复杂的 VQ 压缩,在压缩比为 1:5 和 1:8 时纹理质量尚可。
块 (block) 压缩是一种替代方案,采用固定大小的块压缩。由于每个压缩块包含解码整个瓦片所需的所有信息,解码可以只读取一次内存。
最早的块压缩方案之一是块截断编码 ( BTC - Block Truncation Coding) ,用于压缩灰度图。该算法的核心思想是保存两份样本矩:均值和方差。每个块会通过使用 “a” 和 “b” 两个值进行重建 (见图 4 )。一个压缩块由这两个值和一个位图组成,其中每个位对应一个纹素。
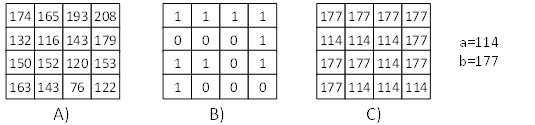
[图4]: BTC 编码的例子。A - 源块,B - 位图,C - 解码块
BTC 编码需要几步来完成:首先,将一张图像拆分成 $M * N$ (通常为 $4 * 4$ ) 大小的小块。然后针对每个区块计算平均值 $\overline{x}$ 和 标准差 $\sigma$ 。接着,构建位图,如果对应的纹素值大于均值则将该位置 1。最后则会根据如下公式计算 $a$ 和 $b$ 的值。
$$
a = \overline{x} - \sigma \sqrt{\frac{m-q}{q}} \tag {1.1}
$$
$$
b = \overline{x} + \sigma \sqrt{\frac{(m-q)}q} \tag{1.2}
$$
其中 $m$ 是一个块中纹素的数目, $q$ 是位图中 1 的数目。
BTC 以简单的编码和轻量的解码算法,实现了良好的压缩比。对于 4x4 的瓦片, 可以达到 1:4 或 2bpp。它曾用于压缩火星探路者的漫游车图像 (15)。
对于彩图,则可以对每个通道分别使用 BTC 算法,能达到 6bpp 的压缩比。不过这种方案会显著降低画质 (见图 5)。而基于 BTC 的 CCC (Color Cell Compression) 算法则能达到 2bpp 到 3bpp 。与 BTC 相似,CCC 把所有值量化为两个值,三条通道共享一张位图。

CCC 的编码算法与 BTC 相似。 首先逐纹素计算亮度 $Y$ 以及平均亮度 $\overline Y$ (见等式$(1.3)$) 。然后通过比较每个纹素的亮度和平均亮度来构建位图。最后确定基色 $ a $和 $ b $。
$$
Y = 0.3 * R + 0.59 * G + 0.11 * B \tag{1.3}
$$
有两种 CCC 算法,第一种以 RGB565 格式直接将 $a$ 和 $b$ 存储在压缩块 中, 因此一个块有 48 位 (每个基色各 16 位,位图 16 位 ) 可以达到 3bpp 的压缩比。第二种则是用一个 8 位的调色板索引替代原有的基准色,从而达到 2bpp的压缩比。当然这个版本的 CCC 也会有调色板压缩的缺点。
CCC 算法兼具高压缩比和低成本硬件实现。由于一个块中只有两种颜色,导致画质损失严重。但其主要思想被应用于现代的纹理压缩格式中,这便是我们接下来要讨论的。
S3TC 系列 #
S3TC (S3 Texture Compression) 最早由S3公司研发并取得专利。自1999年推出以来,它已被广泛接受为行业标准,且至今仍是最常见的压缩方案之一。 微软将 S3TC 引入其 3D 图形API DirectX 6.0,名称为 DXT1。而它的带有 Alpha 通道的纹理的修改即为现在大家所熟知的 DXT2-DXT5。这些格式统称为 DXTC (DirectX Texture Compression) 。DXT1 在 OpenGL 和 OpenGL ES 中也通过 EXT_texture_compression_dxt1 扩展得以支持。这个扩展属于 EXT_texture_compression_S3TC的一部分,其余部分也描述了 DXT3 和 DXT5。
从 DirectX 10 开始,这些格式又被称为 BC1-BC3 (块压缩) 。同时添加了两种新的格式: BC4 和 BC5,它们早期被称为 ATI1/3Dc+ 和 ATI1/3Dc。3Dc格式是由压缩法线图的需求所催生的。DXT1 被设计来压缩彩色数据,在压缩法线数据时效率不高。BC4 和 BC5 的功能在OpenGL中对应 EXT_texture_compresion_rgtc(19) , ARG_texture_compresion_rgtc (20) 以及 EXT_texture_compresion_latc (21)这些扩展。
随着 DirectX 11 的发布 ,又引入了两种新的格式: BC6H, 第一种是针对高动态范围 (HDR - high dynamic range) 纹理的标准格式;而 BC7,则用于处理非常高质量的压缩。在 OpenGL,两种格式都在 ARB_texture_compression_bptc (22) 规范中有所描述。
所有 S3TC 系列格式都使用 4x4 的块。我们会在接下来的小节中详细描述这些压缩格式。
BC1 块 (S3TC/DXT1) #
和 CCC 类似, BC1 也使用 $c0$ 和 $c1$两个基色,以及一张索引表 (位图) (见图6)。不过BC1的索引表每个像素使用了 2 位。这是因为 BC1 允许通过混合两个基色,从而产生 $c2$, $c3$两个新的颜色。所有 $c0, c1, c2, c3$ 一起就构成了一个压缩块的局部调色板。相较于 CCC,引入新色彩无疑让图像质量显著提升。基准色以 RGB565 格式存储,即红色占5bit, 绿色占6bit,蓝色占5bit,能够达到 4bpp 的压缩比。
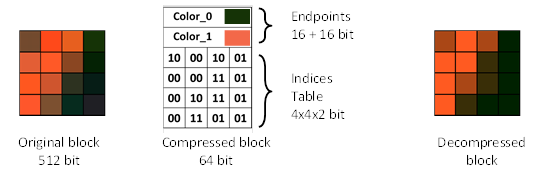
[图6]: BC1 块示例
BC1 块有两种类型,一种不支持透明通道,另一种则支持。
对于第一种,有两种方法定义 $c2$ 和 $c3$。最常见的实现是:基于等式 2.1,分别以 $1:2$ 和 $2:1$的比例进行线性混合。如果我们假设块中的颜色遵循正态分布,等式 2.2 产生的误差会更小。nVidia 的 GPU (23) 中使用了这种方法。此外,从 RGB565 到 RGB888 颜色转换的硬件实现可能会有一些简化,这也能够影响结果。所以相同的压缩数据在不同的硬件上可能产生不同的结果。对于这两种类型,四种颜色都位于 RGB 空间上以 $c0$ 和 $c1$ 为端点的同一线段上。
$$ c2 = \frac {2}{3} c0 + \frac {1}{3}c1 , c3 = \frac {1}{3} c0 + \frac {2}{3}c1 \tag{2.1} $$
$$ c2 = \frac {5}{8} c0 + \frac {3}{8}c1 , c3 = \frac {3}{8} c0 + \frac {5}{8}c1 \tag{2.2} $$
第二种类型的 BC1 块允许编码一个 1 位的 alpha 通道,用于处理具有简单透明度的纹理。每个纹素只有完全透明和完全不透明之分。这种模式也称为穿通 Alpha (翻译存疑)。对于这种类型的 BC1 块,$c3$ 以 $1:1$ 线性混合,而 $c2$ 则表示完全透明。第二种类型的块能够更准确地编码一些没有透明像素的原始图像块。 $$ c3 = \frac{1} {2}c0 + \frac{1} {2}c1 \tag{2.3} $$ 在较为原始的实现里,需要一个额外的位来区分第一种和第二种类型的块,但实际上会使用数据冗余来完成。通过交换端点和重新计算索引来对不同类型的同一块进行编码。这样,如果$c0$ (解释为16位整数) 大于$c1$,则将该块解码为第一类型块,否则为第二种类型的块。
端点的选择对质量有很大的影响。寻找适当的端点 (使误差最小) 很有挑战性。有许多旨在提升速度 (10) (11) (24) 或提高质量 (25) 的编/解码器。
2004年,nVidia 提出了 OpenGL (26) 的NV_texture_compression_vtc扩展,增加了对 3D 纹理压缩的支持,块大小为 4x4x1、4x4x2、4x4x3 或 4x4x4。但是,此扩展没有提供任何新的压缩方法。一个VTC块由1、2、3或4个独立的 S3TC / BC1 块组成,每个块编码一个二维 4x4 切片。
BC2 块 (DXT2/DXT3) #
BC1 格式可以处理 24 位的 RGB 纹理,但不适用于 32 位的 RGBA8888 纹理。Alpha 通道可以用于存储透明度、高光或其他材质属性。Direct3D 中的 BC2 和 BC3 格式则专为此类纹理而设计。 BC2 块占用 128 位,是 BC1 大小的两倍。因此压缩级别为 8bpp。BC2 的一半数据用于保存 4 位精度的 alpha 值 (从 alpha a到alpha b) ,另一半是用于存储 RGB 数据的BC1 (见图7) 。实际上,BC2 相当于压缩了RGB通道的格式为RGBA8884的纹理。颜色通道的解码方式与 BC1 相同。唯一的区别是,它始终被视为第一种类型的块。
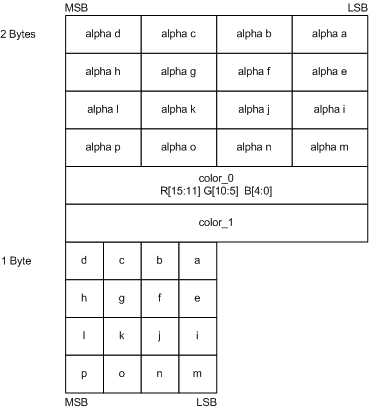
[图7]: BC2 块布局 ( 来源:Programming Guide for Direct3D 10 (27) )
要对半透明纹理进行合成或与背景混合,必须将颜色值乘以 Alpha 通道的透明系数。此时,直接将已经预乘的值存进颜色通道中会比较方便。DXT2 格式比较适用于这种情况。DXT3 块布局与 DXT2 一致,但假定颜色值不进行预乘。不过它们的解码程序都相同。格式名称仅用作区分颜色数据的含义。因此,BC3 格式并不对上述情况进行区分,解释数据的责任就落在了应用程序这边。
需要注意的一点,在进行材质过滤之前,一定要先将颜色值乘以 Alpha。否则过滤的结果就会有误。在进行 Alpha 混合时,预乘 alpha 模式要优于直接存储初始值,并能够简化硬件实现。想了解更多预乘 Alpha 的信息,可参见 «Jim Blinn’s Corner: Compositing, Part 1: Theory» (28).
BC3 块 (DXT4/DXT5) #
BC3 的块 (与 BC2 类似) 由两段64位数据组成:一段是 Alpha 数据,另一段是颜色数据。颜色部分同样使用了 BC1 的格式,但 Alpha 部分则以压缩形式存储 (见图8)。除了通道数外,Alpha 通道的压缩与 DXT1 类似:有两个 8 位精度的端点,3 位的索引表,因此能在局部调色板上 8 选 1。
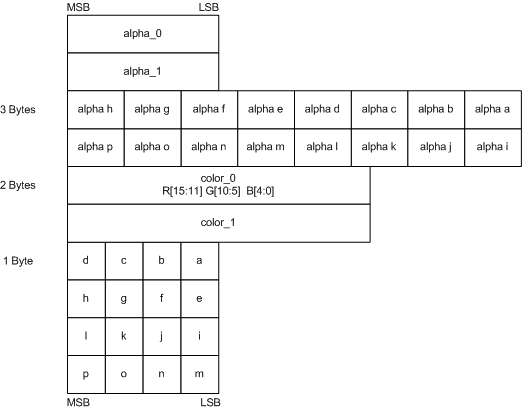
[图8]: BC3 块布局 ( 来源:Programming Guide for Direct3D 10 (27) )
这里解码时也使用了与 BC1 相同的数据冗余技巧。如果alpha_0 > alpha_1,则通过线性插值计算局部调色板的六个附加值。否则,仅插值四个值,其余两个对应最大和最小有效值。代码 1 描述了 Alpha 通道的调色板填充过程。BC1 子块始终被视为第一种类型的块,使用公式 2.1 或 2.2。
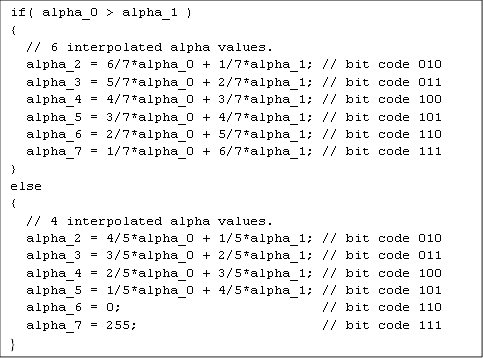
[代码1]: Alpha 通道的调色板填充 ( 来源:Programming Guide for Direct3D 10 (27) )
和 DXT2 / DXT3 类似,Direct3D 9 中的 DXT4 / DXT5 格式仅在颜色通道数据的含义上有所不同。DXT4 会假定存储的颜色数据已经预乘 Alpha,而 DXT5 则假定不预乘。 Direct3D 10 中只有一种 BC3 格式,因此不区分这两种情况。
通常,BC3 能提供比 BC2 更好的图像质量,后者更适用于低一致性的 alpha 数据。
BC4 块 (ATI1/3Dc+) #
BC4 块 (图9) 只是 BC3 块的 alpha 部分。它用于单通道纹理,例如高度图或高光贴图。解码后的值与红通道相关联。
[图9]: BC4 块布局 ( 来源:Programming Guide for Direct3D 10 (27) )

[代码2]: BC4 块调色板填充 ( 来源:Programming Guide for Direct3D 10 (27) )
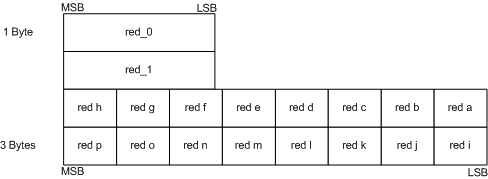
BC4块与 BC3 alpha 部分的使用相同的解码方式。但通常单通道数据 (例如位移贴图) 直接将浮点范围限制在 $[0, 1]$ 或 $[-1, 1]$ 内会更方便。因此,通常会直接将其对应到 red_0 和 red_1 两个端点。代码 2 描述了范围为 $[-1, 1]$ 时的调色板填充 。
BC5 块 (ATI2/3Dc) #
3Dc 格式最初由 ATI 专门为压缩法线贴图而开发,因为 DXT1 并不能达到此类数据要求的质量。顾名思义,法线贴图包含每个纹素的法线的信息,使得可以在不增加几何图形的复杂度的情况下,计算出更高细节的光照 (见图1.B)。法线信息会以范围为 $[-1, 1]$ 的浮点数的形式分别存储在各个颜色通道中。BC1 的问题是不同颜色通道的值通过共用的索引表耦合在一起。这一点用在常规 RGB 图像没有问题,但不适用于通道间互不相关的法线贴图。并且由于局部调色板较小,BC1 显著限制了梯度值。 基于以上原因,使用BC1压缩的法线贴图的质量较差 (见图10) 。

[图10]: 法线贴图压缩( 来源:ATI 3Dc 白皮书 (29) )
根据定义,法向向量具有单位长度,因此只需要指定 $x$, $y$ 值,就可以依照公式 2.4 来计算 $z$。而对于切线空间法向量 (24),$z$ 值始终为正。 $$ z = \pm \sqrt {1 - x^2 - y^2} \tag{2.4} $$ BC5 其实是一个双重的 BC4。它允许独立存储两个通道 (见图 11)。 同时 BC5 拥有更大的局部调色板,在处理双通道图像时可以获得远超 BC1 的效果。
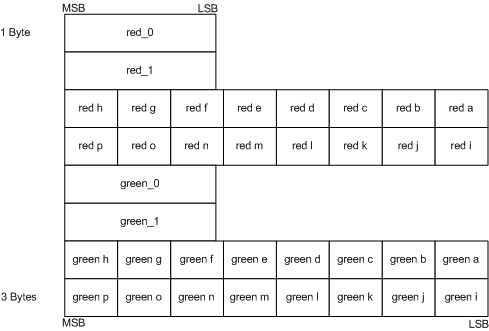
[图11]: BC5 块布局( 来源:Programming Guide for Direct3D 10 (27) )
每个子块的解码过程与 BC4 完全相同。 默认情况下,不会计算 $z$ 坐标,因为 BC5 格式可用于任意两种成分的纹理,解码后的值会填充红色和绿色通道。对于法线贴图,可以在像素着色器中计算丢失的 $Z$ 轴坐标。
OpenGL中对应的扩展名为EXT_texture_compression_rgtc (19) ,ARB_texture_compression_rgtc (20) 和EXT_texture_compression_latc (21) 。_rgtc和_latc版本均同时描述了单通道 BC4 块和双通道 BC5 块。在使用_rgtc时,未打包的数据将解释为红和绿通道的值。 在_latc的情况下,未打包的数据将解释为亮度,或亮度和 alpha 值。
BC6H 和 BC7 的通用信息 #
限制 BC1 压缩质量的主要因素有:
- 端点的精度低 (RGB565)。此外,通道中不均匀的位分布可能会导致颜色偏移。例如,很多纯灰色的颜色不能用RGB56 “精确” 地表示:RGB565 (12,24,12) 就是 RGB888 (99,97,99) 略带紫色,而 RGB565 (12,25,12) 则是偏绿的 RGB888 (99, 101, 99 )。
- 局部调色板较小。一个块中只能使用 4 种颜色。
- 所有颜色都位于 RGB 色彩空间中的同一条直线上。 如果原始块中的颜色没有映射到线段,则压缩块可能看起来很差 (见图 12)。
[图12]: BC1 “坏掉的” 压缩块示例
在新格式中,上述问题已经通过提高端点精度以及存储最多 3 对端点解决了。两种格式都使用 128 位块,因此得到了 8bpp 的压缩比。而根据块类型,压缩块会使用不同的字段集,每块字段集的大小也不同。因此可以针对每个块选择最佳编码。这种灵活性极大减少了压缩带来的伪影,但同时也显著增加了压缩复杂度。块类型的数量在 BC6H 中增加到 14 个,BC7 增加到 8 个。 与 BC1 不同的是,块类型会在压缩块的第一位中明确设置。 块类型也称为块模式 (block mode)。
在利用多个端点对时,一个瓦片会被分为多个纹素组,称为子集 (subsets)。每个子集拥有自己的端点对。有两组和三组纹素的块各拥有64个预定义分区集 (partition set) 。因此只需要将分区 ID 存储在压缩块中就可以指定特定分区。图13 展示了其中一些分区集。
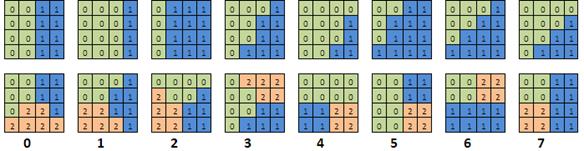
[图13]: 两组(上) / 三组(下) 纹素块的前 8 个分区集
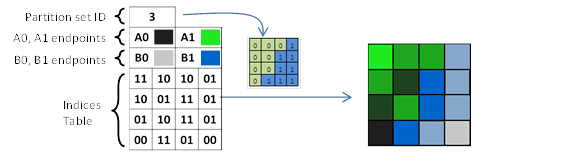
[图14]: 双区瓦片的 BC6H / BC7 块解码的简化示例
与之前的格式一样,索引表中的值指定了端点混合的比例。 分区 ID 用于确定每个纹素的端点对。 简化的解码示例如图 14 所示,其中 $A0-A1$ 和 $B0-B1$ 端点对分别用于子集 0 和子集 1。 索引的大小可以是 2 到 4 位。 因此,每个子集中可用的中间颜色数量从 2 到 14 不等。
BC6H 和 BC7 格式有一个重要特性:位级精确解码。硬件必须返回与参考解码器一致的结果,即使是无效块也应如此。有关所有块模式的详细信息可以参考 Direct3D 11 文档 (30) 和 OpenGL ARB_texture_compression_bptc 扩展规范 (22) 。从 OpenGL 4.2 (31) 开始,此规范成为 OpenGL Core Profile 的一部分。
端点插值 #
DXT1 格式并没有指定插值 (混合) 程序,因此不同的硬件会使用不同的权重 (见 BC1 ( S3TC / DXT1 )) 。新格式中总是会使用 64 作为系数,并严格定义插值权重。BC7 插值的伪代码如 [代码3] 示,其中 indexprecision 表示单个索引的比特大小,可以是 2,3,4比特。

[代码3]: BC7 解压过程中使用的插值 (来源: Programming Guide for Direct3D 11 (30) )
BC6H 的插值过程与之相似,只是使用有符号值,这里不再赘述。
索引编码 #
DXT1 使用了数据冗余来帮助编码。在 BC6H / BC7 中也采用了同样的技巧来缩小索引表,每个端点对编码为 1 bit。例如,考虑左上角的 texel 0 的索引。如果其最高位为 1,则可以交换相应的端点,使其变为 0。于是总是可以通过重排端点使得子集里的某个索引的最高位为 0。这样的索引被称为锚索引 ( anchor indexes ),且该索引的最高位也不会存储在压缩块中。texel 0 的索引必定是子集 0 的锚索引。图 15 展示了一些分区集的锚索引:
BC7 块 #
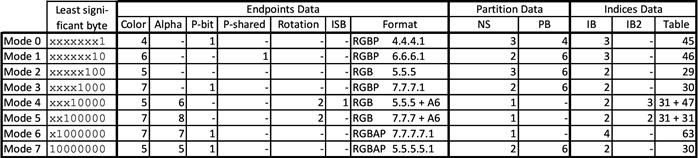
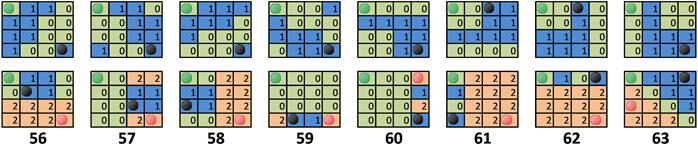
表 1 展示了所有 BC7 块模式下不同字段的大小 ( NS 和 Format 列除外 ),单位为比特。
- Color - 每个颜色通道占用的大小
- Alpha - alpha 通道的大小
- P-bit - 是否有 P-bit
- P-Shared - 是否有共享 P-bit
- Rotation - ”Rotation“ 的字段大小
- ISB - 是否有 idxMode/ISB 索引选择位 (Index Selection Bit)
- NS - 子集数量 ( Number of Subsets )
- PB - 分区索引的字段大小
- IB - 索引表中的索引的字段大小
- IB2 - 第二个索引表中的索引的字段大小
- Table - 索引表的总大小
表 1 中的块模式为最低位在右侧的最低有效字节 (LSB) 的值。 在下文取自 Direct3D 11 MSDN 页面 (30) 的图中 ,模式字段显示为最低位在左侧。 这两个值是序列正好是反的。
BC7 在模式 0 下的 PB 字段仅有 4 位 (见图 16 )。因此,只有前 16 个分区集可用。而在其他多子集模式中,所有 64 个分区集都可用。
新字段 P-bit 的含义与 RGBP/RGBAP 缩写中相应的字母 P 的含义,可以看看 BC7 Mode 0 的例子 (见图 16 ) 。块中存储了三个 RGB444 端点对,每个端点都有一个 P 位。端点会在反量化 (译注:量化为数字信号处理术语,此处翻译参考了 MSDN) 之前扩展到 RGB555,而 P-bit 会被解释为每个通道的最低位。相较于直接存储 RGB555,现在每个端点直接省下了 2 比特,精度损失却不超过 1 比特( 所有颜色通道里总共只会有 0 或 1 比特失真 )。
BC7 在模式 1 时会使用 P-Shared 位。与 P-bit 相似,不过该位会在端点对中共享。

[图16]: BC7 模式 0 的块布局 (来源: Programming Guide for Direct3D 11 (30) )
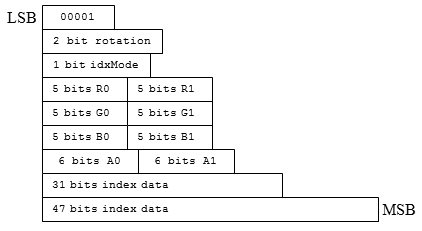
[图17]: BC7 模式 4 的块布局 (来源: Programming Guide for Direct3D 11 (30) )
BC7 在 Mode 4 (见图 17) 和 Mode 5 下会有两个独立的索引表,可以用来独立存储四个通道中的一个。适用于像法线贴图这种,其中一个通道与其他通道无关的情况。这两个模式同样适用于分别存储色彩和 Alpha 值,这点和 BC3 有些相似。任何一个通道都可以成为拥有独立索引表的那个,Rotation 字段用于确定是具体哪个通道。
在BC7 Mode 4下,索引表占用的位长度不一样,所以精度也会不一样。ISB 字段 (图17中的 idxMode) 用于确定表中有多少位用于独立通道,多少位用于其余通道 (译注:MSDN) 。
BC6H 块 #
BC6H 格式旨在压缩高动态范围的纹理,即 HDR (High Dynamic Range)。仅支持不带 alpha 的 RGB 图像。通道值以有符号或无符号的 16 位浮点数表示。 因此解码器也需要支持两种模式。不仅如此,解码后的数据还需要满足 IEEE 754 half/binary16 格式 (见图 18) 。解码后,数据会以 32-bit 浮点形式返回给 shader。 BC6 的有符号和无符号版本的块模式相同。通常意义上,图 18A 对应有符号的浮点数格式,而 18B 对应无符号浮点数。不过在实践中,解码过程仅会使用整数算数运算。有符号、 无符号的解码模式仅在反量化期间对符号位的处理有所不同。
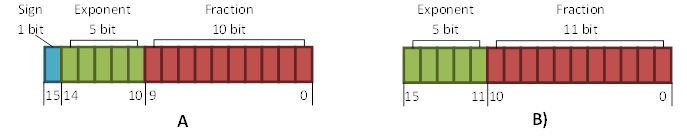
[图18]: 16位精度的浮点数格式。A - signed, B - Unsigned.
BC6H 共有14种块类型 (见表2 ) , 只支持 1 到 2 个纹素组。PB 字段 (Partition ID) 始终为 5 位。 因此,只有前 32 个分区集可用。在大多数情况下 (模式 10 和 11 除外) ,端点使用增量编码存储:直接存储一个端点,再存储其他端点的偏移量。
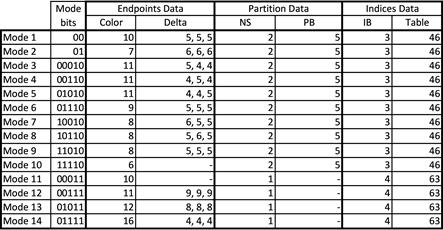
[表2]: BC6H 在不同块模式下的各字段的尺寸
上文中提到,即便最终值被解释为浮点数,解码和插值时也只会使用整数算数运算。其原理基于浮点数的编码 (图18) ,其中指数偏移值位于高位,小数部分 (隐含 1 ) 位于低位。将这样的二进制编码解释为整数也同样具有数学意义。尤其是,相邻的浮点数也具有相邻的整数表示。对于任意正的 $A$ 和 $B$ , 如果 $A > B$, 那么二进制解释成为整数时也满足 $A>B$ 。代码 4 中展示了作用于浮点数的整数运算示例。当线性插值作用于具有不同指数偏移的浮点数的整数表示时,变换中将含有指数 (对数) 运算 (见图 19 ) 。

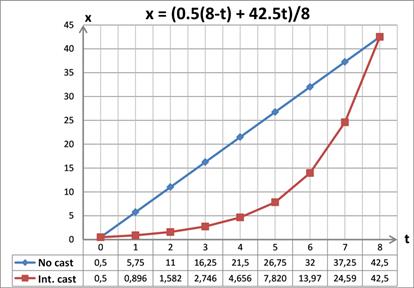
[图 19]: 插值示例。 “No cast” - 直接对浮点数使用线性插值,“Int. Cast” - 将浮点数转换为整型后再线性插值。
解码过程包含如下四步:
符号扩展和 delta 变换反置。 在有符号 BC6H 的情况下,压缩块中存储的所有端点和偏移量 (delta) 都进行了符号扩展 (符号位扩充到了高位) ,在无符号 BC6H 的情况下,只有偏移量进行了符号扩展。 此外,对于所有块类型,除了模式 10 和模式 11 之外,其余的端点都是通过将相应的偏移值添加到直接存储的端点来恢复的。 在模式 10 和模式 11 块中,所有端点都直接存储。
端点的反量化。 对于无符号 BC6H,反量化过程如
(((X << 16) + 0x8000) >> uBitsPerComp),其中uBitsPerComp是直接存储的端点的一个通道的大小 (bits) 。 边界条件 (zero, max value) 会单独考虑。线性插值过程与 BC7 类似。考虑到有符号和无符号格式的存在,未量化值的范围为 -32768 到 65535。因此,插值器使用了17-bit的有符号代数运算。
最后的调整或反量化。 由于在 IEEE 754 中使用指数字段的最大值 (全部为 1) 来编码特殊的
INF/NaN值,因此有符号格式下,插值之后的值按 $31/32$ 缩放,而无符号格式按 $31/64$ 缩放。 最终结果是一个合法的 16 位半浮点数。
ETC 系列 #
ETC (Ericsson Texture Compression) 格式最初是针对移动设备开发的。 今天 (译注:2014 年),它是基于 Android 系统的设备的标准压缩方案。 OpenGL ES 和 WebGL 通过 (33) 和 WEBGL_compressed_texture_etc1 (34) 扩展支持 ETC1 格式。 ETC1 和 ETC2 规范则从 OpenGL 4.3 (35) 以来,成为 OpenGL Core Profile的一部分。
第一个版本的压缩方案 PACKMAN 于 2004 年推出 (3)。 而后在 2005 年,被称为 iPACKMAN 的增强版被提出 (36)。 该版本更为人知的名称是 ETC1,广泛应用于移动设备。 该方案的后续发展,催生了 2007 年 ETC2 格式 (37)。

[图20]: PACKMAN的核心思想。(来源: ETC2 论文 (37))
ETC 压缩的核心是基于:人眼对亮度而不是色度更敏感这一事实。 因此,每个子块中仅存储一种基色 (ETC1/ETC2 由两个子块组成) ,但亮度信息是按每个纹素存储的 (见图 20)。 亮度偏移由单个整数值设置,最终会和每一个颜色分量相加。 一个子块内只有四种不同的亮度偏移可用,即只有四种不同的颜色可用。 可以认为这些颜色就是一个局部调色板。
ETC1 (38) (39) 和 ETC2 (40) (41) 的对应专利属于瑞典爱立信公司 (Telefonaktiebolaget L. M. Ericsson)。
PACKMAN #
如果压缩块占用的位数与总线宽度相同,则可以避免管线停顿,从而简化硬件实现 (3)。由于移动设备在内存大小和总线宽度方面受到严格限制,PACKMAN 决定使用 2x4 的块。因此压缩块仅占用 32 位,压缩比为 4bpp,等于 BC1 的压缩比。
块中仅存储一种 RGB444 基色 (译注:12bits) 。 其他颜色是通过改变纹素的亮度取得的 (译注:每个纹素 2bits, 共16bits) 。 虽然基本思想与 BC1 区别巨大,但解码过程却非常相似。 首先,恢复四色局部调色板。 然后根据索引表从该调色板中挑选颜色 (见图 21) 。 不过由于块尺寸小,只剩下 4 位用于存储亮度变化和调色板中的三种附加颜色。 因此,这 4 位的编码被直接用于指向预定义的亮度集 (见表 3) 。
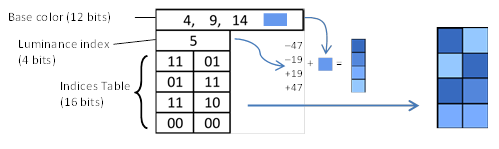
[图21]: PACKMAN 块解码示例。
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Luminance 00 | 2 | 4 | 6 | 12 | 8 | 19 | 28 | 42 |
| Luminance 01 | 8 | 12 | 31 | 34 | 50 | 47 | 80 | 127 |
| Luminance 10 | -2 | -4 | -6 | -12 | -8 | -19 | -28 | -42 |
| Luminance 11 | -8 | -12 | -31 | -34 | -50 | -47 | -80 | -127 |
[表3]: PACKMAN 亮度码表的前半部分
可以看到,表 3 的下半部分是上半部分对应的负数,这点能用于简化解码器。 亮度组 8-15 (未在表中显示) 的值为0-7的 2 倍 。 这张表基于随机值生成,然后以将测试图像的误差降到最小为指标来进行优化 (3) 。
ETC1 ( iPACKMAN ) #
单一的低精度 (RGB444) 基色是 PACKMAN 中图像质量的主要限制因素。 这个问题在 ETC1 中得到了解决。
ETC1 瓦片的大小是 4x4,它由两个子块组成,和在 PACKMAN 中的块一样。 这些子块可以垂直或水平排列,为瓦片内基色的选择提供了更大的灵活性。 差分块 (Differential) 类型的引入,提升了精度。第一个子块的基色以 RGB555 精度存储,第二个基色存储 3bit 差异值。 将两种基色直接以 RGB444 格式存储的块称为独立块 (Individual) (见图 22) 。
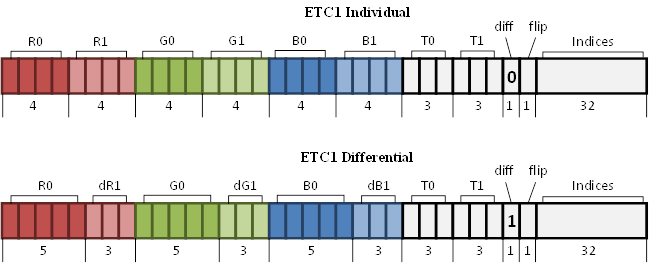
[图22]: ETC1 的块布局。
| N | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Luminance 00 | 2 | 5 | 9 | 13 | 18 | 24 | 33 | 47 |
| Luminance 01 | 8 | 17 | 29 | 42 | 60 | 80 | 106 | 183 |
| Luminance 10 | -2 | -5 | -9 | -13 | -18 | -24 | -33 | -47 |
| Luminance 11 | -8 | -17 | -29 | -42 | -60 | -80 | -106 | -183 |
[表4]: ETC1 和 ETC2 的亮度码表
为了给块类型编码保留空间,亮度码本减少到 8 组,因此索引大小 (图 22 上的 T0 和 T1) 下降到 3 bits 。显然,码本中的值也经过重新计算 (见表 4) 。 因此腾出了 2 bits 空间,其中一个 “diff” 位用于指定块类型,另一个 “flip” 位指定子块的垂直或水平排列。
ETC2 #
差分模式和可旋转子块显着提高了图像质量。 然而在每个子块中只有一种基色可用,这导致颜色变化剧烈的图块会被压缩后会有更高的错误率。 此外,即使是平滑梯度在 ETC1 下也可能会产生问题。
ETC2 通过引入额外的块模式来解决上述问题。 这些新模式对在 ETC1 方案中无效的块进行编码,使得 ETC2 解码器与 ETC1 格式完全兼容。 当基色和偏移的总和溢出了 5 bit 的有效范围 [0, 31] 时,差分块中就会出现无效组合。 而这些 “无效” 块会使用一种新模式进行解码。 能够导致溢出的所有 R0 和 dR1 组合如表 5 示。
| R0 | dR1 | R0, dR1 binary | Encoded value |
|---|---|---|---|
| 0 | -4 | 00000 100 | 0000 |
| 0 | -3 | 00000 101 | 0001 |
| 0 | -2 | 00000 110 | 0010 |
| 0 | -1 | 00000 111 | 0011 |
| 1 | -4 | 00001 100 | 0100 |
| 1 | -3 | 00001 101 | 0101 |
| 1 | -2 | 00001 110 | 0110 |
| 29 | 3 | 11101 011 | 0111 |
| 2 | -4 | 00010 100 | 1000 |
| 2 | -3 | 00010 101 | 1001 |
| 30 | 2 | 11110 010 | 1010 |
| 30 | 3 | 11110 011 | 1011 |
| 3 | -4 | 00011 100 | 1100 |
| 31 | 1 | 11111 001 | 1101 |
| 31 | 2 | 11111 010 | 1110 |
| 31 | 3 | 11111 011 | 1111 |
[表5]: 所有会导致溢出的
R0和dR1组合。
此类块中的有效载荷为 59 bits。 64 bits 中的 1 bit 用于 diff 位,8 bits 用于 R0 和 dR1 值,还剩 55 bits。 但是,可以使用 R0 和 dR1 的两个最低位来编码附加信息 (表 5 中的 Encoded value 列) 。
绿通道中的溢出可用于编码另一种模式。 但载荷会更少,因为这个块在红色通道中一定不能有溢出。 否则会被视为前一种类型的块。 不过好在只占用了 1 bit。 R0 的两个最高位的不相等可以保证不会有溢出,这点可以在表 5 中观察到。在第二种模式中可以使用总共 58 bits。
类似地,蓝通道溢出的第三种模式提供 57 bits 有效载荷。 表 6 中列出了所有块模式。
| diff | Overflow | Overflow | Overflow | |
|---|---|---|---|---|
| Block mode | diff | R | G | B |
| Individual | 0 | - | - | - |
| 59-bit mode (T-mode) | 1 | yes | - | - |
| 58-bit mode (H-mode) | 1 | no | yes | - |
| 57-bit mode (Planar mode) | 1 | no | no | yes |
| Differential | 1 | no | no | no |
[表6]: ETC2 的块模式。
与独立模式和差分模式类似, T 形块和 H 形块都使用低 32 bits 存储索引表。但局部调色板使用的是不同的方式解码:$A(r_0, g_0, b_0)$ 和 $B(r_1,g_1,b_1)$ 以 RGB444 格式压缩在 T 块中, 其余 3 bits 则用于编码 d 值。A,B 的值将反量化为 RGB888。另外两个局部调色板的颜色用这个方法计算: $C0 = (A - (d, d, d))$,$C1 = (A + (d, d, d))$。因此局部调色板在色彩空间中呈现 T 形 (见图23) 。此模式适用于那些,大多数点位于一条线上,而有些纹素又是其他颜色的块。这里需要强调一点,距离 d 是间接存储的:3bits 字段用于存储查找表 (LUT) {3,6,11,16,23,32,41,64} 的索引,T 形块和 H 形块相同 。
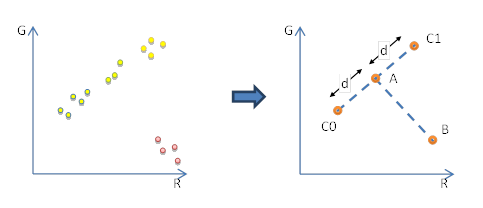
[图23]: T形块的原始块和调色板的颜色分布。(基于: ETC2 论文 (37) )
H 模式与 T 模式非常相似,存储着颜色 A、B 以及 d 值的索引。但局部调色板中使用的是 c0、c1、c2、c3 而非 A、B、C0、C1 (见图 24) 。这些颜色在 RGB 空间中形成 H 形。此模式适用于那些,颜色位于两条线上的块。然而 H 形块的有效载荷要比 T 形块少 1 比特,但是又必须存储同样多的数据 (两个 RGB444 颜色和一个用于查询 d 值的索引) 。这里使用了 BC1 中的技巧 (译注:冗余编码) ,由于 H 形是对称的,因此 A、B可以互换,基于此就可以补足缺失 bit 的信息。
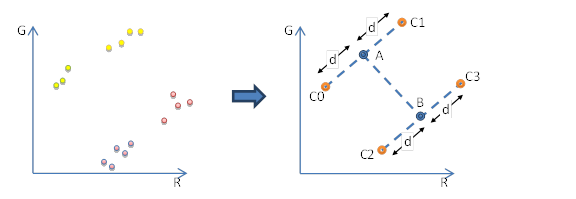
[图24]: H形块的原始块和调色板的颜色分布。(基于: ETC2 论文 (37) )
Planar 模式用于对平滑梯度编码。所有 57bits 用于存储 RGB676 格式的三种基色 C0、CH、CV (见图25) ,所有纹素的颜色使用线性滤波方程 3.1 计算,其中 X 和 Y 的范围为 [0, 3]。
$$
C(x, y) = \frac{x(C_H-C_0)}{4} + \frac{y(C_V-C_0)}{4} + C_0 \tag{3.1}
$$

[图25]: ETC2-Planar 块的基色坐标以及解压示例。
除了 RGB 版本,OpenGL 中还有一个"穿通 Alpha" 版本的ETC2: 一个 RGBA8881 纹理。其中没有独立块类型,因此仅仅通过是否溢出来区分 T、H 和 Planar 模式。Diff-bit 用于指定差分子模式。如果是 “1” ,差分块像之前一样解压,如果是 “0”,索引 “10” 保留给全透明颜色 (见表 7) 。 T、H 和Planar 块的解码过程保持不变。
| N | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Luminance 00 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Luminance 01 | 8 | 17 | 29 | 42 | 60 | 80 | 106 | 183 |
| Luminance 10 | T | T | T | T | T | T | T | T |
| Luminance 11 | -8 | -17 | -29 | -42 | -60 | -80 | -106 | -183 |
[表7]: ETC2 “穿通 Alpha” 的亮度码表。(T - 透明 (transparent) )
EAC #
ETC2 无法维护许多类型纹理所必需的、完整的 alpha 通道。此外,ETC2 不支持对二分量图像进行高质量的压缩,因此不适用于法线贴图。对于这种情况,可以使用名为 EAC 的 64bits 块。EAC 以高精度编码单通道的 4x4 的块。OpenGL中,还定义了如下包含 EAC 作为子块的格式:
COMPRESSED_RGBA8_ETC2_EAC/COMPRESSED_SRGB8_ALPHA8_ETC2_EAC(类似于BC3) —— 是一个 128 bits 块,一个 64 bits ETC2 块存储 RGB 通道,一个 64 bits EAC 块存储 alpha 通道。COMPRESSED_R11_EAC/COMPRESSED_SIGNED_R11_EAC(类似BC4) —— 是一个存储红通道的 64 bits EAC 块。COMPRESSED_RG11_EAC/COMPRESSED_SIGNED_RG11_EAC(类似BC5) —— 是一个 128 bits 块,由两个 64 bits EAC 块组成,用于存储红色和绿色通道。
简洁起见,这里将仅详细描述COMPRESSED_RGBA8_ETC2_EAC 块。 所有 ETC 和 EAC 选项在 OpenGL 4.4 Core Profile 规范 (42) 中有详细描述。
EAC 压缩方案复用了 ETC 中的思路,但针对单分量图像:整个 4x4 切片仅存储一个基值,并且每纹素索引用于调制其亮度 ( $Luninance$ ) (见图 26) 。 和上文中一样,有一个预定义的亮度码本 (见表 8) 。 特定亮度集 (N) 的索引直接存储在压缩块中。唯一新增的就是亮度修饰符的值需乘以 Mul 值,Mul值也直接存储在压缩块中。纹素值使用公式 3.2 计算,其中 clamp255 将值限制在 [0, 255] 范围内。
$$
A = clamp255(base+Mul \times Luninance) \tag{3.2}
$$
基值以 8 bits 精度存储 (见图 26) 。 使用了 3 bits 索引,因此局部调色板中最多可以使用八个不同的值。
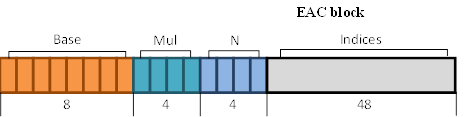
[图26]: EAC 的块布局。
| N | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Luminance 000 | 3 | -3 | -2 | -2 | -3 | -3 | -4 | -3 | -2 | -2 | -2 | -2 | -3 | -1 | -4 | -3 |
| Luminance 001 | -6 | -7 | -5 | -4 | -6 | -7 | -7 | -5 | -6 | -5 | -4 | -5 | -4 | -2 | -6 | -5 |
| Luminance 010 | -9 | -10 | -8 | -6 | -8 | -9 | -8 | -8 | -8 | -8 | -8 | -7 | -7 | -3 | -8 | -7 |
| Luminance 011 | -15 | -13 | -13 | -13 | -12 | -11 | -11 | -11 | -10 | -10 | -10 | -10 | -10 | -10 | -9 | -9 |
| Luminance 100 | 2 | 2 | 1 | 1 | 2 | 2 | 3 | 2 | 1 | 1 | 1 | 1 | 2 | 0 | 3 | 2 |
| Luminance 101 | 5 | 6 | 4 | 3 | 5 | 6 | 6 | 4 | 5 | 4 | 3 | 4 | 3 | 1 | 5 | 4 |
| Luminance 110 | 8 | 9 | 7 | 5 | 7 | 8 | 7 | 7 | 7 | 7 | 7 | 6 | 6 | 2 | 7 | 6 |
| Luminance 111 | 14 | 12 | 12 | 12 | 11 | 10 | 10 | 10 | 9 | 9 | 9 | 9 | 9 | 9 | 8 | 8 |
[表8]: EAC 的 Mod 值
例如,考虑一个压缩块,其中 base = 0b11011110,mul = 0b1010,N = 0b1101,特定纹素的索引为 0b0012。转换为十进制后,base = 222,mul = 10,N = 13。在此示例中 N 对应于亮度集 {-1, -2, -3, -10, 0, 1, 2, 9} (表 8 中的第 13 列) ,纹素索引 0012 从该集合中选取 mod 值,mod = -2。将这些值代入公式 3.2 后,$A=clamp255(222 + 10 × (-2))$ ,即, $A=202$。
PVRTC 系列 #
PVRTC (PowerVR Texture Compression) 格式 (14) 是由 Imagination Technologies (43) (44) (45) (46) 持有专利,专为 PowerVR 图形核心系列设计的。 用于 Apple 移动设备,例如 iPhone 和 iPad。 不久前针对新的图形核心,引入了增强版的 PVRTC2。 OpenGL ES 中 IMG_texture_compression_pvrtc (47)、IMG_texture_compression_pvrtc2 (48) 和 EXT_pvrtc_sRGB (49) 扩展支持这两种格式。 对应的的 WebGL 草案扩展为 (50)。
相较于本文中的其他技术,PVRTC 或许是最封闭的。除了 Simon Fenney (14) 最早的关于 PVRTC 论文 《使用低频信号调制的纹理压缩》(Texture Compression using Low-Frequency Signal Modulation) 以及Imagination Technologies 网上的几篇博客之外(51) (52) (53),没有其他公开的技术信息了。即使是 OpenGL 和 WebGL 的扩展标准中也没有提供任何实现细节。尽管如此,crunch 纹理压缩库的开发者 R.Geldreich 为 PVRTC 压缩器的实现也作出了相当一部分努力 (54) (55)。
PVRTC 压缩技术比较有趣,和前述中提到的技术有很大不同。严格来讲,PVRTC 并非基于块的编解码器。核心思想与小波压缩有一些共通之处,即整张图像被分成低频和高频信号。低频信号由两张低分辨率图像 A 和 B 呈现,在两个维度上都按比例缩小了 4 倍。高频信号是完整分辨率低精度的调制信号 M。要解码整张图像,首先应放大图像 A 和 B,然后使与调制信号 M 混合,其中调制信号 M 指定了每个纹素的混合权重 ( 见图 27) 。
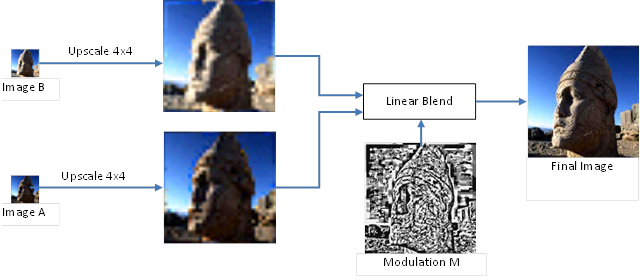
[图27] : PVRTC的核心思想 (源自: PVRTC 的论文 (14))
有别于其他压缩方案,PVRTC 利用了跨块边界的颜色的相似性。因此这种方案本身支持平滑梯度。同时没有块伪影。此外,它还利用了实际纹素坐标与其颜色值的相关性。类似 BC 和 ETC 的方案利用了块内颜色的相似性,但只关注于颜色集合,而非特定颜色的位置。 也就是说,图块内的所有纹素都可以随机重排,同时 BC 编解码器仍可以生成完全相同的局部调色板。 但 PVRTC 可能会丢失压缩纹理中的一些高频细节。
Imagination Technologies 已将对 PVRTC2 的支持添加到其最新的 PowerVR 图形核心系列 – PowerVR Series5XT 和 PowerVR Series6 (51) (52) (53)。 PVRTC 和 PVRTC2 两个版本都有 4bpp 和 2bpp 模式。
随着 PVRTC2 的发布,产生了新的命名混乱。 在原始 PVRTC 格式引入时,PVRTC2 和 PVRTC4 缩写分别成为 2bpp 和 4bpp 模式的流行标签。 但由于缩写之一与新格式的名称相同。 因此建议使用以下别名:PVRTC 4bpp、PVRTC 2bpp、PVRTC2 4bpp、PVRTC2 2bpp (或 PVRTCII 2bpp/4bpp) 。
PVRTC 4bpp #
从性能的角度来看,访问三个不同的图像来解包单个 texel 或 tile 看起来不是很妙。 因此,所有数据以 64 比特的块存储在一处。 每个块由图像 A 的一个像素、图像 B 的一个像素和相应的 4x4 调制系数区域组成 ( 见图 28) 。
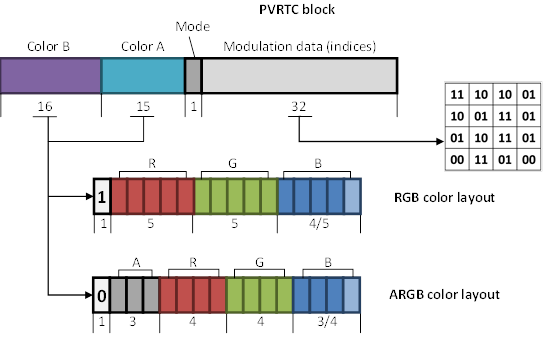
[图28]: PVRTC 4bpp 的块布局。
任意 A 和 B 颜色都能以 RGB 或 RGBA 格式存储。 两个颜色字段中的最高位决定使用哪种格式。 但是,色域 A 比色域 B 小一位。因此,色 A 可以用 RGB554 或 ARGB3443 编码,色 B 用 RGB555 或 ARGB3444 编码。
通常来讲,必须读取四个相邻的 PVRTC 块才能对任意纹素进行解包 (见图 29) 。 因此需要恢复已经放大的图像 A 和 B 的相应区域。 4 个相邻 PVRTC 块的包含的信息就能够解码一个 5x5 块。 解码示例如图 30 所示。
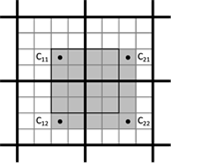
[图29]: 可以使用 4 个相邻 PVRTC 块解码的纹理区域。

[图30]: PVRTC 4bpp 解码示例。
放大过程使用双线性滤波。然后使用逐纹素索引确定图像 A 、B 的混合权重 (见表 9 ) 。Mode-bit (见图 28) 用于穿通 alpha 模式。此模式允许对 1 位 alpha 通道进行编码,而不损失 RGB 通道的精度。 当模式位为“1”时,索引“10”保留给全透明值。
| Index (modulation data) | Modulation value (Mode=0) | Modulation value (Mode=1) |
|---|---|---|
| 00 | 0/8 | 0/8 |
| 01 | 3/8 | 4/8 |
| 10 | 5/8 | 4/8 (+ «punch through alpha») |
| 11 | 8/8 | 8/8 |
[表9]: PVRTC 中使用的模式值
需要说明的一点是,尽管基本思想不同,但 BC1 方案可以被视作 PVRTC 的一个使用阶跃函数执行放大的特例。
初看起来读取四个块可能对性能影响会很大。 但其实纹理缓存减少了负面影响,因为相邻区域需要更少次数的内存访问。 此外,双线性以及更复杂的过滤类型对于 3D 渲染几乎是不可或缺的。因此,每个纹理获取操作至少需要 2x2 源纹素。 当这些纹素位于相邻的块中时,在 BC/ETC 压缩的情况下也必须读取两个或四个块。 对于任何 PVRTC、BC 或 ETC 方案,最坏的情况都需要四个块。
由于单块影响的面积大,因此压缩过程会复杂一些。 修改任意基色 (A 或 B) 会改变最近的 7x7 区域内的所有纹素 (见图 31) 。此功能使得动态纹理合成和创建纹理图集变得更加复杂。因此,纹理图集的各个元素必须有边界填充。
[图31]: 一个 PVRTC 块影响的区域。
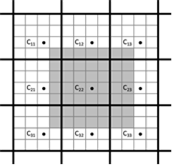
PVRTC 2bpp #
PVRTC 有一种压缩比极高的模式,仅有 2bpp。它与 4bpp 模式相似,并且使用相同的块布局 ( 见图 32) 。不过图像 A 和 B 在水平维度上又缩小了一半。因此 ,32 位调制字段必须保存 8x4 纹素的调制信息。Mode-bit 指定了调制数据的编码。 如果是 $0$,则每纹素存储 1-bit 在调制字段中。 否则,将存储 2-bit 索引,但仅对以棋盘模式排列的一半纹素。随后通过平均相邻的两个或四个调制值来计算剩余纹素的调制值。
[图32]: PVRTC 2bpp 块的布局。
PVRTC 2bpp 解码的简化示例如图 33 所示。假设所有四个压缩块中的 Mode位均为0。
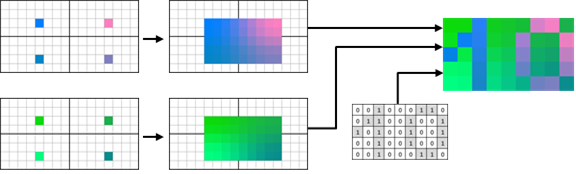
[图33]: PVRTC 2bpp (Mode = 0) 解码示例。
PVRTC2 4bpp #
PVRTC2 增强了压缩质量,并消除了 PVRTC 的一些不足之处。例如,PVRTC2 支持 NPOT 纹理 (Non Power Of Two) ,两个维度的分辨率都可以不为 2 的幂。此功能与压缩方案没有直接关系,但需要一定的硬件支持。 尤其是,硬件应该能够正确计算被请求的压缩块的地址。
类似于之前的做法,可以通过引入新类型的块或解码模式以改善质量。在 PVRTC 中,基色 A 和 B 各自可以独立选择使用 RGB 或 ARGB 存储格式。 然而通常是两种颜色具有相同格式。因此,在 PVRTC2 中仅使用一个位 (Opacity) 来指定两种颜色的格式,第二个位 (Hard) 用于编码新模式 (见图 34) 。
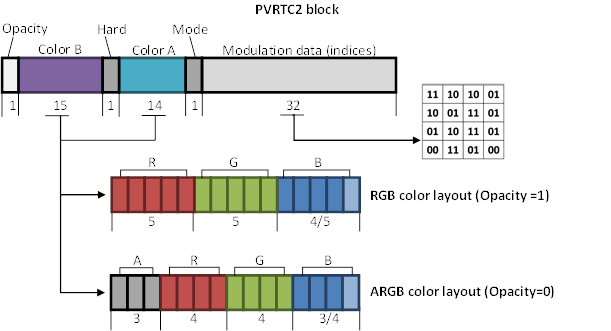
[图34]: PVRTC2 块的布局。
“Hard”位和“Mode”位一起能够表示四种解码模式 (见表 10) 。
| «Hard» bit | «Mode» bit | Decoding mode |
|---|---|---|
| 0 | 0 | 标准双线性插值 |
| 0 | 1 | 穿通 alpha |
| 1 | 0 | 无插值 |
| 1 | 1 | 局部调色板 |
[表10]: PVRTC2 4bpp 的块模式。
“标准双线性插值” 和 “穿通Alpha” 的解码方式与上文提到的 PVRTC 相同,不过在 alpha 模式中会有一些变化。在 “穿通 alpha” 模式下透明的索引也会将颜色值设为 0。 这其实是预乘 alpha (参阅 BC2 块 (DXT2/DXT3)) ,方便进行混合和过滤。另一个变化与 alpha 值反量化过程有关。 现在,A 和 B 图像的 alpha 值以些微不同的方式转换为 8 比特格式,如代码 5 所示;AlphaA3、AlphaB3 – 是 3 bit 打包的 alpha 值,而 AlphaA8、AlphaB8 – 是未打包的 8 bit 值。如果仔细观察,会发现 AlphaA8 不会等于 “255”,AlphaB8 不会等于 “0”,不过倒也不是什么问题。
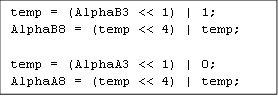
[代码5]: PVRTC2 解压时 Alpha 转换至 8 位。
新的模式,将 “Hard “位设置为 “1”,简化了纹理图集的创建,并改善了某些对 PVRTC 块来说相对困难的情况下的压缩质量。在 “无插值 “模式下,图像A和B被放大,没有插值。相反,所有相应的像素都有相同的基础颜色。随后的解码过程与PVRTC中的解码过程相同。必须指出的是,” Hard " 标记会影响偏移量为 [2, 2] 的 4x4 纹素区域 (见图35) 。对于边界块,” Hard " 标志区域是环绕 ( wrap ),就和环绕的纹理映射一样。

[图35]: Hard 标记影响的区域。
这种模式的解码例子见图 36。其类似于 S3TC 压缩。事实上,如果所有相邻的块都有标志 Hard=1 和 Mode=0,那么对应于一个 PVRTC 块的纹理解码将与 BC1的解码方案相同。因此,这种模式可用于对纹理图集中单个元素的边界进行编码。
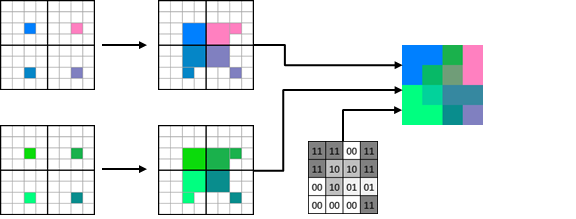
[图36]: PVRTC2解码示例, Hard = 1, Mode = 0 (无插值)。
在 “局部调色板 “模式下 (Hard=1,Mode=1) ,A和B不会混合。局部调色板由来自四个相邻的 PVRTC2 块的 A 、 B 对填充,共有8种颜色。但一个索引的大小只有2 比特,这意味着这 8 种颜色中只有 4 种可用于每个特定的纹素。图 37 显示了每个纹素可用的颜色集,其中描述了解码所需的四个 PVRTC2 块。P 块指定了灰色阴影区域纹素的解码模式。每个块中存储的 A 和 B 的颜色分别表示为 Pa, Pb, Qa, Qb, Ra, Rb, Sa, Sb。每一个纹素的颜色都可以在放大的 4x4 区域内描述。唯一的例外是最左上方的texel P* :它的颜色是由 Pa 和 Pb 混合得到的。
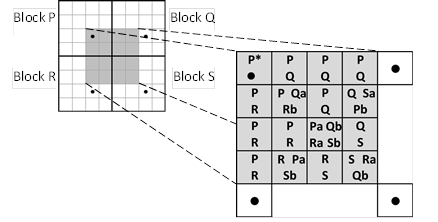
[图37]: 逐像素可访问的局部调色板模式。 (来源: 美国专利 8526726 (46))。
ASTC 格式 #
ASTC (自适应可扩展纹理压缩) 是由 ARM 和 AMD 联合开发,并于2012年提出的(56)。格式规范 (57) 被 Khronos 联盟批准并在 OpenGL 中采用。在 OpenGL 和 OpenGL ES 中对应的扩展为KHR_texture_compression_astc_hdr (58)。从 Mali-T628 和 Mali-T678 开始,所有 ARM 图形核心都有 ASTC 硬件支持(59)。专利 (60)(61)(62)(63) 归 ARM 所有。尽管如此,仍需要指出,ASTC 是完全开放和免专利费的。
以下每个用例都对压缩方案有自己的要求:
- 支持从 1 到 4 个分量的纹理。虽然单通道纹理也可以使用BC7、PVRTC2或ETC2来存储,但空通道上大量bit被浪费掉了。
- 在通道之间数据无相关性的情况下,拥有可以接受的质量。这对于法线图和 RGBA 图像来说非常重要。
- 支持 LDR 和 HDR。BC6H可用于HDR纹理压缩,但它不支持alpha通道。
- 跨平台。特别是:PVRTC 只在 iOS 平台上可用,BC6H/BC7 在移动设备中缺失,ETC 不被桌面级 GPU 所支持。对于跨平台应用程序的开发者来说,有诸多不便。
- 比特率/质量比的灵活性。根据纹理类型,不同程度的压缩伪影是可以接受的,因为不同图像的可压缩性是不同的。前文中提到的格式里,能提供的比特率/质量选项的不超过两个 (BC1/BC7或PVRTC 4bpp/2bpp) 。如果不能使用 5bpp 的压缩级别 (如果4bpp的质量略显不足) ,就必须使用8bpp的选项。带宽增加了一倍,但质量却没有明显改善。
- 支持 2D 和 3D 纹理。
新的压缩方案是在考虑到所有这些要求的情况下制定的。ASTC格式有一个固定大小的 128 位块。然而,对于 2D 纹理,编码的瓦片尺寸从4x4到12x12 纹素不等,3D 纹理则是从3x3x3到6x6x6。所有支持的瓦片尺寸和相应的比特率可以在表11中找到。“Increment”一栏显示,比特率可以在非常细致的级别中进行调整。在ASTC 规范中,瓦片尺寸也被称为块足迹 (block footprint)。
| № | 2D textures | 3D textures | ||||
|---|---|---|---|---|---|---|
| Tile size | Bit rate | Increment | Tile size | Bit rate | Increment | |
| 1 | 4x4 | 8.00 bpp | 125% | 3x3x3 | 4.74 bpp | 133% |
| 2 | 5x4 | 6.40 bpp | 125% | 4x3x3 | 3.56 bpp | 133% |
| 3 | 5x5 | 5.12 bpp | 120% | 4x4x3 | 2.67 bpp | 134% |
| 4 | 6x5 | 4.27 bpp | 120% | 4x4x4 | 2.00 bpp | 125% |
| 5 | 6x6 | 3.56 bpp | 114% | 5x4x4 | 1.60 bpp | 125% |
| 6 | 8x5 | 3.20 bpp | 120% | 5x5x4 | 1.28 bpp | 125% |
| 7 | 8x6 | 2.67 bpp | 105% | 5x5x5 | 1.02 bpp | 120% |
| 8 | 10x5 | 2.56 bpp | 120% | 6x5x5 | 0.85 bpp | 120% |
| 9 | 10x6 | 2.13 bpp | 107% | 6x6x5 | 0.71 bpp | 120% |
| 10 | 8x8 | 2.00 bpp | 125% | 6x6x6 | 0.59 bpp | - |
| 11 | 10x8 | 1.60 bpp | 125% | |||
| 12 | 10x10 | 1.28 bpp | 120% | |||
| 13 | 12x10 | 1.07 bpp | 120% | |||
| 14 | 12x12 | 0.89 bpp | - |
[表 11]: ASTC 块大小和压缩比。
ASTC是文章中描述的最为灵活的格式,因为它支持 LDR、HDR、2D 和 3D 纹理,最多有4个通道。甚至支持低于 1bpp 的比特率。
概念上讲,ASTC 类似于 S3TC/BC7:一个压缩块中最多存储四个端点对和插值权重,只支持预定义的分区,特定的分区由分区ID指定,也存储在一个块中。在弱相关的情况下,该通道会存储一个独立的索引表。每个独立的编码被称为一个平面。
或许 ASTC 最主要、最有趣的创新是用小数位编码整数值的技术,称为BISE。同时,BISE可以在硬件中有效实现。
有界整数序列编码 (Bounded Integer Sequence Encoding (BISE)) #
有界整数序列编码,或称 BISE,解决了如下抽象问题:从大小为 $N$ 的字母表中给定等概率的符号序列, 找到一种编码,使得能够在常数时间复杂度内使用最少的硬件消耗提取第 $i$ 个符号,并允许相同硬件设计能够用于多种不同大小的字母表,同时具备存储效率(64)(65)。
例如,考虑一个由 5 个整数组成的序列,其中每个整数可以是 0,1 或 2(译者注:5 位的 3 进制数)。使用标准二进制编码时,需要为每个值分配 2 位,总共 10 位。但不同序列的数量是 $3^5=243$,小于 $2^8=256$。因此,可以用 8 比特对整个序列进行编码,每个值的比特率为 1.6。换句话说,可以用8比特来表示5 位的 3 进制数。
现在,考虑任意长度的序列,其中每个值都属于范围$[0, N-1]$,其中 $N=3*2^n$。每个值都可以用一个三进制位和 n 个比特来表示。假设 $N=12$,那么满足该条件的任何值都可以用以下形式表示: $X = t2^2 + b_{1}2^1 + b_{0}2^0$,其中 $t$ 是一个三进制位,$b_0$ 和 $b_1$ 是比特位。整个序列可以被划分为五组值,最后一组会在必要时填充 0 。二进制形式下,一个特定的组可以表示为一个比特串 $t_4B_4t_3B_3t_2B_2t_1B_1t_0B_0$,其中 $t_i$ 是一个三进制位的 2 比特表示,$B_i$ 是一个值的剩余比特位( 译注: 即上文中的 $b_0$ 和 $b_1$)。只要三进制位与比特信息保持这种相关性,就可以用比特串 $T_{[7]}B_4T_{[6:5]}B_3T_{[4]}B_2T_{[3:2]}B_1T_{[1:0]}B_0$ 保存这五组值。其中 $T_{[i:j]}$ 为 $T$ 的各个比特,这段数据要比原先短 2 比特。
事实证明,这种编码能够保留尾部的零。例如,如果我们序列中的最后一组被填充了两个零 (所以$t_4B_4$和$t_3B_3$是零) ,那么 $T_{[7]}B_4$ 和 $T_{[6:5]}B_3$ 是零,它们不需要被存储。因此,任何长度的序列,假如其数值范围从 $0$ 到 $3*2^n-1$,都可以用接近于理论上的最小的比特率进行编码。同时,其中的任意值能以最小的硬件消耗容易的提取出来。
同样的推理也可以应用于$N=5*2^n$的序列。这里,3 个五进制数 (基数为5的数字) 可以用 7 位来编码,因为 $5^3=125$ 小于 $2^7=128$ 。因此,使用三进制数和五进制数的BISE技术在存储方面都是是有效率的 (见图38) 。
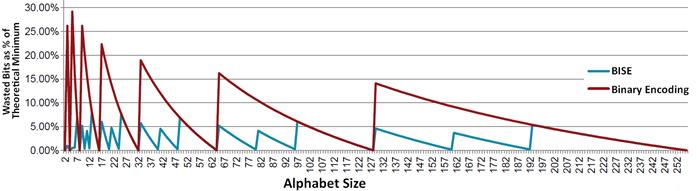
[图38]: ISE 与 二进制编码的存储效率。(来源: CGDC2013 的 ASTC intro (65))
ASTC 压缩方案使用 BISE 对颜色端点和插值权重进行编码。而且它还为插值权重提供了硬件友好的二次方除数。一个三进制位编码为三个权重 ${0, ½, 1}$ 中的一个,一个五进制位编码为 ${0, ¼, ½, ¾, 1}$ 这五个中的一个。此外,BISE允许对端点的精度进行细致的改变。表12中描述了所有使用三进位或五进位的彩色端点编码的情况。
| Range | Number of used digits | Number of used digits | Number of used digits | Bit size | Bit size |
|---|---|---|---|---|---|
| Trits | Quints | Bits | Effective | Theoretical Minimum | |
| 0..5 | 1 | 1 | ~ 2.60 | 2.58 | |
| 0..9 | 1 | 1 | ~ 3.33 | 3.32 | |
| 0..11 | 1 | 2 | ~ 3.60 | 3.58 | |
| 0..19 | 1 | 2 | ~ 4.33 | 4.32 | |
| 0..23 | 1 | 3 | ~ 4.60 | 4.58 | |
| 0..39 | 1 | 3 | ~ 5.33 | 5.32 | |
| 0..47 | 1 | 4 | ~ 5.60 | 5.58 | |
| 0..79 | 1 | 4 | ~ 6.33 | 6.32 | |
| 0..95 | 1 | 5 | ~ 6.60 | 6.58 | |
| 0..159 | 1 | 5 | ~ 7.33 | 7.32 | |
| 0..191 | 1 | 6 | ~ 7.60 | 7.58 |
[表12] : 用于颜色反量化的参数。
BISE解码之后,解包的数值被反量化为标准范围[0, 255]。
其他改进 #
ASTC 还改进了分区模式。BC6H 和 BC7 压缩方案也使用了预定义的分区集表 (见图13) ,但这种方法不适合 ASTC,因为它支持大量的瓦片尺寸,支持更多的区域,还增加了分区ID字段的大小 (10位,而BC7是6位) 。ASTC 的分区模式是用一个特殊的哈希函数生成的,它为每个纹素分配一个分区索引。这个函数将纹素在瓦片中的位置、分区ID、瓦片大小和分区数量作为输入,并输出一个分区索引。该函数很简单,可以用硬件实现。该函数也用于 3D 纹理。图 39 中描述了 8x8 瓦片的所有分区模式。

[图39]: ASTC 8x8 块的分区集。(来源: ARM Mail Graphics blogs (66))
ASTC 的一个更显著的特点是内插权重的编码方式。S3TC 系列方案使用每个顶点的索引来设置插值权重。根据块的类型,索引的大小可以是 2、3 或 4 比特。然而,对于 12x12 瓦片来说,即使每个像素使用 1bit 的索引,也无法存储在一个 128 位块。因此,ASTC 为权重和纹素提供独立的网格大小。例如,对于 12x12 的瓦片,只能存储 4x6 的权重网格。在解码阶段,权重网格被双线性地放大到瓦片大小。不过虽然看起来像,但是它和简单的瓦片缩放并不一样。例如,平滑的梯度通常可以用一个小的权重网格来表示,如 2x2。因此有更多的比特可用于端点。同时尖锐的边缘和颜色过渡可以用适合的分区模式进行编码。权重网格的大小是根据每个块来选择的。因此某些具有强烈垂直特征的瓦片,可以用 4x2 或 8x4 的权重网格进行编码。
所有这些配置数据 (网格大小、分区数量、端点格式) 都必须存储在一个压缩块中。虽然不得不牺牲一些颜色数据位,因而可能降低图像质量,但这种方法带来了很好的灵活性,并且大大增强了压缩质量。ASTC 允许在每个块中进行不同的比特权衡,任意瓦片都可以在分区、端点和权重之间的分布选用最合适的比特分布进行编码。事实证明,即使在较低的比特率下,ASTC也能够提供比 PVRTC、BC1-BC5 和 ETC 更好的质量。PSNR (译注:峰值信噪比) 增益平均为 1.5dB 至 2dB,大多数观察者 (译注:推测此处数值为 ASTC 对比其他压缩格式获得的增益 ) 大约能察觉 0.25dB 的增益。BC6H的质量与之相当,而 BC7 平均比 ASTC 多出0.5dB。不过在 8bpp 时,ASTC 和 BC7 压缩图像的 PSNR 质量都在45dB左右,这种差异很难从视觉上发现 (56) 。
此外,ASTC 是第一个支持 3D 纹理的标准压缩方案,它利用了所有三个维度的颜色相关性。nVidia 的 OpenGL(26)的 VTC 扩展也是针对3D纹理的,但它只是把一个3D瓦片分成2D片,使用BC1方案进行压缩。ASTC 则使用 3D 权重网格和分区,利用分区模式生成器来压缩整个3D瓦片。不过权重网格是用单线法而非三线插值法进行放大的 (67) 。整个 3D 瓦片的压缩比分片压缩的 PSNR 高出 2dB (68) 。
另外,ASTC 的所有特征都是 “正交 “的,即任何特征都可以独立使用,例如可以用两个弱相关的HDR通道来压缩一个三维纹理。
ASTC 块 #
首先是一些全局解码参数,这些参数对任何特定的纹理都是一样的。因此,没有必要在压缩块中存储这些。
动态范围 (LDR/HDR)
纹理尺寸(2D/3D)
瓦片尺寸
输出色彩空间 (sRGB/RGB)
而每块指定的数据如下。
权重网格大小
权重范围 (用于BISE解码
权重值
分区的数量
分区模式 ID
颜色端点模式
颜色端点数据
平面的数量 (1或2)
平面到通道的分配
纹理可以被编码为单通道、双通道、三通道或四通道图像。但解码后的值总是以 RGBA 格式输出。在LDR sRGB 模式下,颜色值以 8 位整数返回,否则以 16 位浮点数返回。图40展示了 ASTC 块的布局。

[图40]: ASTC 块的布局。
除了 “BlockMode “和 “Part “字段,所有字段的长度都是可变的。
“Part” 字段指定了分区的数量 (减一) 。在双平面模式下,分区的数量必须是1、2或3。“BlockMode” 字段指定了平面数、权重范围和权重网格的大小。“ConfigData” 和 “MoreConfigData” 字段指定每个端点对的端点模式。
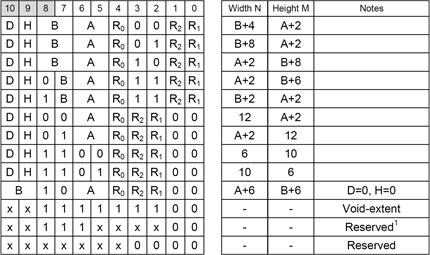
如果是 2D 瓦片,“BlockMode” 由5个字段组成。A、B、R、D、H (表13) 。 特殊的 “void-exten” 模式有一个单独的编码,用于单色瓦片。void-exten 块还允许识别附近的单色区域。可以缩短获取相同的块的过程,并进一步减少内存带宽占用。
[表13] : 2D 块的 BlockMode 字段布局。(源自: ASTC 技术手册 (57))
A、B 字段分别指定权重网格的宽度 (N) 和高度 (M) 。D位 (双倍) 被设置为表示双平面模式。R字段 (范围) 和H位 (高精度) 指定重量范围 (见表14) 。注意,由于R字段的编码,为了避免产生歧义,位 $R_1$ 和 $R_2$ 不能同时为零, (见表13) 。
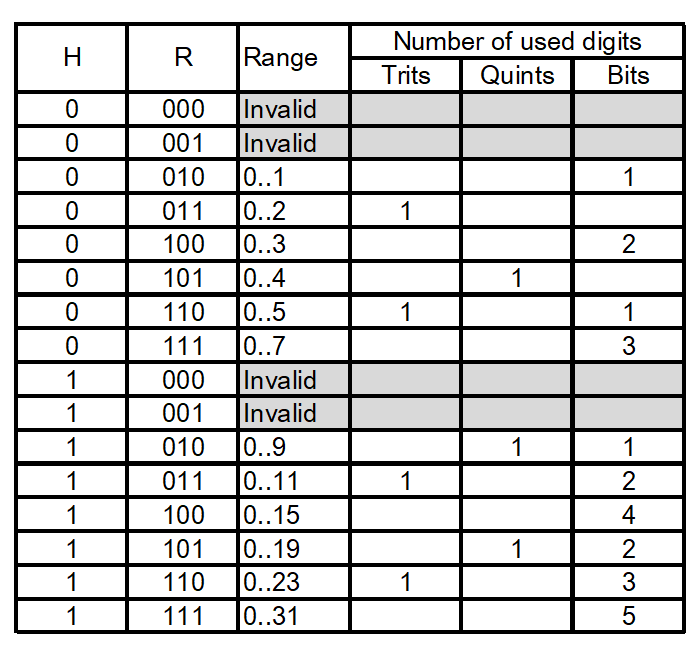
[表14] : 权重编码的参数
ConfigData 和 MoreConfigData 指定了端点对的编码,每个端点对都可以有独立的编码模式。共有16种编码模式:10 种 LDR 格式和 6 种 HDR 格式。然而,HDR 纹理可以使用其中任何一种。所有这些端点格式都是基于以下基本方法之一:
- 独立性。两个k位的值直接存储。
- base + offset (类似于ETC的差分编码) 。第一个值为base, 用 (k+1) 位存储。第二个值为 offset, 用 (k-1) 位存储。
- base + scale。两个RGB值由四个数值 (R、G、B、s) 表示。颜色一等于 (R,G,B) ,颜色二等于 (sR,sG,sB) 。
在 ASTC 规范 (57) 和 ASTC 原始论文 (56) 中有所有端点模式和 BISE 编码的详细描述。
从概念上讲,ASTC块的解码是这样进行的。BlockMode 字段用于确定权重范围和权重网格的大小。权重数据从压缩块的尾部读取,并使用BISE进行解包。之后,权重被反量化为 [0, 64] 范围。如果权重网格的尺寸小于瓦片的尺寸,则使用双线性插值进行升格。
之后,Part 字段用于指定分区的数值。分区模式 ID 从块中读出,然后针对每个纹素生成哈希作为分区索引。
给定分区数量,还可以利用 ConfigData 和 MoreConfigData 字段计算标量的总值,该值会被用于端点编码 (端点可以有不同数量的通道,不同的端点存储模式下会使用不同数量的值) 。然而,这些标量值的范围在 BISE 解码时必须是已知的,因为该范围并没有被明确指出。在权重和分区数据解码阶段之后,就可以知道可用于彩色端点数据的比特数。颜色端点的值会使用适用于上述比特数的最大范围的值来存储。端点被解压缩和反量化。
端点对会根据分区索引来选择。端点的颜色则使用插值权重来混合。
简要描述上文讨论的所有纹理压缩格式 #
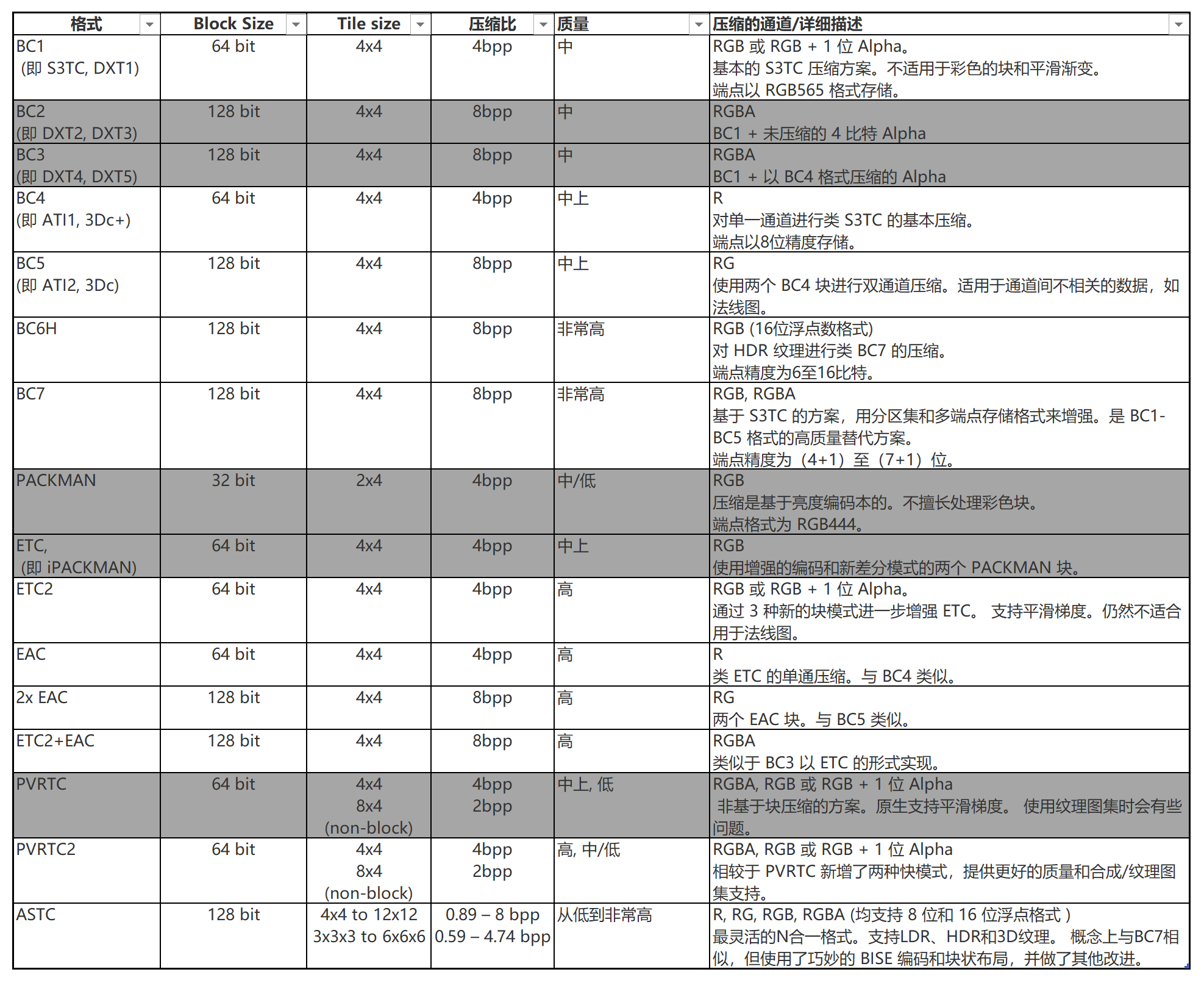
[表15] : 本文所讨论的所有纹理压缩格式的简述 (已经弃用的方案使用灰色背景)
对压缩格式的选择受目标硬件限制。例如,S3TC 系列只在 PC 上可用。根据特定的移动平台,可能支持 ETC 或 PVRTC (一些设备支持 BC1-BC5,但并不常见) 。只有一些最新的移动GPU支持ASTC格式。
在 S3TC 系列中:
- BC7能够为RGB和RGBA纹理提供最好的质量,可以完全取代BC2和BC3
- BC1 可用于较低质量的RGB压缩
- BC4 和 BC5 用于单通道和双通道纹理
- BC6H 用于 HDR 纹理
PVRTC 被 PVRTC2 所取代,后者不仅提高了质量,解决了其前身的一些问题。PVRTC2 也支持 RGB 和 RGBA 纹理。
ETC2 完全取代了 PACKMAN 和 ETC 格式,但只支持RGB纹理。另外,ETC2 和 EAC 块的某些组合提供与 BC1-BC5 格式相仿的功能。
ASTC格式支持任何类型的纹理,并提供多种比特率以供选择。
结论 #
纹理压缩在现代计算机图形中占重要地位。现如今,许多智能手机的显示屏已经具有 FullHD 分辨率 (1920x1080) ,而桌面 GPU 的则面向的是 4K 和 8K 这样的超高清分辨率 (分别为 3840x2160 和 7680x4320) ,大大增加了内存带宽要求。预计纹理的分辨率也会增长,高压缩比变得越来越重要。
由于不同纹理的可接受的压缩伪影水平不同,针对每种纹理,需要选择能够保证图像质量的前提下,可以减少内存带宽的合适的压缩比。在可选格式中,ASTC 是最好的一种。虽然桌面 GPU 尚不支持,但我们相信 ASTC 会因为它的灵活性和质量而取代所有其他格式。在任何给定的比特率下,ASTC 的质量都优于除了 BC7 外的所有其他格式。广泛采用 ASTC 也将简化跨平台应用开发。
至于纹理压缩的未来,目前的策略可能朝着增加块和瓦片的大小的方向发展。也有可能使用可变比特率 (VBR) 方案,进一步提高压缩的灵活性。
这项工作由 AMD 公司 (Advanced Micro Devices, Inc.) 支持,并获得了俄罗斯联邦政府 074-U01号财政拨款的部分支持。作者在此感谢 Vladimir Kibardin 帮助撰写文章的英文版本。
译者在此感谢原作者 T. Paltashev 与 I. Perminov 在翻译过程中提供的帮助。特别感谢 Zhongliang Chen 在校对过程中给出的专业建议和帮助。
References #
McDonald John. Eliminating Texture Waste: Borderless Ptex. 2013. GDC2013.
Inada T. and McCool M. D. Compressed lossless texture representation and caching. New York, NY, USA : ACM, 2006. Proceedings of the 21st ACM SIGGRAPH/EUROGRAPHICS symposium on Graphics hardware. pp. 111-120.
Strom Jacob and Akenine-Moller Tomas. PACKMAN: Texture Compression for Mobile Phones. . New York, NY, USA : ACM, 2004. ACM SIGGRAPH 2004 Sketches.
van Waveren, J.M.P. id Tech 5 Challenges: From Texture Virtualization to Massive Parallelization. Siggraph. Part of Beyond programmable shading course. 2009.
Olano M., et al., et al. Variable Bit Rate GPU Texture Decompression. 2011. Computer Graphics Forum, vol. 30, pp. 1299–1308.
Strom Jacob and Wennersten Per. Lossless Compression of Already Compressed Textures. Strom Jacob and Wennersten Per. s.l.: Eurographics Association. High Performance Graphics, 2011, pp. 177-182.
Vorobev Andrey. 3DGiTogi iyul 2001 goda — Vliyanie tekhnologii S3TC (FXT1) na kachestvo i skorost [3DGiTogi ]uly 2001 - impact of technology S3TC (FXT1) on quality and speed]. 2001. Available at: http://www.ixbt.com/video/0701i-video-s3tc1.html
WesleyandSmith Ian N., Liska Milos and Holub Petr. Implementation of DXT Compression for UltraGrid. Implementation of DXT Compression for UltraGrid. s.l. : CESNET, 2008.
Petr Holub, et al., et al. GPU-accelerated DXT and JPEG compression schemes for low-latency network transmissions of HD, 2K, and 4K video. Future Generation Computer Systems, vol. 29, № 8, 2013, pp. 1991-2006.
van Waveren, J.M.P. Real-Time DXT Compression. Id Software. 2006. Tech. rep.
FastDXT. Available at: http://www.evl.uic.edu/cavern/fastdxt/
Fast CPU DXT Compression. 2012. Available at: http://software.intel.com/en-us/vcsource/samples/dxt-compression
Ilya Perminov. Povyshenie effektivnosti obrabotki dinamicheski szhimaemykh tekstur [Improvement of Dynamic Texture Compression]. Nauchno-tekhnicheskiy vestnik informatsionnykh tekhnologiy, mekhaniki i optiki [Scientific and Technical Journal of Information Technologies, Mechanics and Optics], vol. 6 (88), 2013 г., стр. 164-165.
Fenney Simon. Texture compression using low-frequency signal modulation. Eurographics Association, 2003. Graphics Hardware. pp. 84-91.
Rover Camera Instrument Description. Available at: http://pdsimg.jpl.nasa.gov/data/mpfr-m-rvrcam-2-edr-v1.0/mprv_0001/document/rcinst.htm
Iourcha Konstantine I., Hong Zhou and Nayak Krishna S. System and method for fixed-rate block-based image compression with inferred pixel values. US Patent 5,956,431 US, 1999.
EXT_texture_compression_dxt1 extension specification. 2008. Available at: http://www.opengl.org/registry/specs/EXT/texture_compression_dxt1.txt
EXT_texture_compression_s3tc extension specification. 2013. Available at: http://www.opengl.org/registry/specs/EXT/texture_compression_s3tc.txt
EXT_texture_compression_rgtc extension specification. 2008. Available at: http://www.opengl.org/registry/specs/EXT/texture_compression_rgtc.txt
ARB_texture_compression_rgtc extension specification. 2009. Available at: http://www.opengl.org/registry/specs/ARB/texture_compression_rgtc.txt
EXT_texture_compression_latc extension specification. [Online] 2009. Available at: http://www.opengl.org/registry/specs/EXT/texture_compression_latc.txt
ARB_texture_compression_bptc extension specification. [Online] 2011. Available at: http://www.opengl.org/registry/specs/ARB/texture_compression_bptc.txt
Castano Ignacio. GPU DXT Decompression. 2009. Available at: http://www.ludicon.com/castano/blog/2009/03/gpu-dxt-decompression/
van Waveren, J.M.P. and Castano, Ignacio. Real-Time Normal Map DXT Compression. Real-Time Normal Map DXT Compression. 2008.
Brown Simon. DXT Compression Techniques. 2006. Available at: http://www.sjbrown.co.uk/2006/01/19/dxt-compression-techniques/
NV_texture_compression_vtc extension specification. 2004. Available at: http://www.opengl.org/registry/specs/NV/texture_compression_vtc.txt
Block Compression (Direct3D 10). Available at: http://msdn.microsoft.com/en-us/library/windows/desktop/bb694531
Blinn James F. Jim Blinn’s Corner: Compositing, Part 1: Theory. IEEE-CGA, Vol. 14, 1994, pp. 83-87.
3Dc™ White Paper. Available at: http://www.hardwaresecrets.com/datasheets/3Dc_White_Paper.pdf
Texture Block Compression in Direct3D 11. Available at: http://msdn.microsoft.com/en-us/library/windows/desktop/hh308955
The OpenGL Graphics System: A Specification Version 4.2 (Core Profile). The OpenGL Graphics System: A Specification Version 4.2 (Core Profile). 2012.
Sovremennaya terminologiya 3D grafiki [Modern terminology 3D graphics]. Available at: http://www.ixbt.com/video2/terms2k5.shtml#hdr
OES_compressed_ETC1_RGB8_texture extension specification. 2008. Available at: http://www.khronos.org/registry/gles/extensions/OES/OES_compressed_ETC1_RGB8_texture.txt
WEBGL_compressed_texture_etc1 Extension Draft Specification. 2013. Available at: http://www.khronos.org/registry/webgl/extensions/WEBGL_compressed_texture_etc1/
The OpenGL Graphics System: A Specification Version 4.3 (Core Profile). The OpenGL Graphics System: A Specification Version 4.3 (Core Profile). 2013.
Strom Jacob and Akenine-Moller Tomas. iPACKMAN: High-quality, Low-complexity Texture Compression for Mobile Phones. New York, NY, USA : ACM, 2005. Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Conference on Graphics Hardware. pp. 63-70.
Strom Jacob and Pettersson Martin. ETC2: Texture Compression Using Invalid Combinations. Aire-la-Ville, Switzerland : Eurographics Association, 2007. Proceedings of the 22Nd ACM SIGGRAPH/EUROGRAPHICS Symposium on Graphics Hardware. pp. 49-54.
Strom Jacob and Akenine-Moller Tomas. Multi-mode alpha image processing. US Patent 7,693,337 US, 2010.
Multi-mode image processing. US Patent 7,734,105 US, 2010.
Multi-mode image processing. US Patent 7,751,630 US, 2010.
Pettersson Martin and Strom Jacob. Texture compression based on two hues with modified brightness. US Patent 8,144,981 US, 2012.
The OpenGL Graphics System: A Specification Version 4.4 (Core Profile). The OpenGL Graphics System: A Specification Version 4.4 (Core Profile). 2013.
Fenney Simon. Method and apparatus for compressing data and decompressing compressed data. US Patent 7,236,649 US, 2007.
Method and apparatus for compressing data and decompressing compressed data. US Patent 7,242,811 US, 2007.
Method and apparatus for compressing data and decompressing compressed data. US Patent 8,204,324 US, 2012.
Method and apparatus for compressing data and decompressing compressed data. US Patent 8,526,726 US, 2013.
IMG_texture_compression_pvrtc extension specification. 2012. Available at: http://www.khronos.org/registry/gles/extensions/IMG/IMG_texture_compression_pvrtc.txt
IMG_texture_compression_pvrtc2 extension specification. 2012. Available at: http://www.khronos.org/registry/gles/extensions/IMG/IMG_texture_compression_pvrtc2.txt
EXT_pvrtc_sRGB extension specification. 2013. Available at: http://www.khronos.org/registry/gles/extensions/EXT/EXT_pvrtc_sRGB.txt
WEBGL_compressed_texture_pvrtc Extension Draft Specification. 2013. Available at: http://www.khronos.org/registry/webgl/extensions/WEBGL_compressed_texture_pvrtc/
51.Voica Alexandru. PVRTC: the most efficient texture compression standard for the mobile graphics world. [Online] January 2013. Available at: http://withimagination.imgtec.com/index.php/powervr/pvrtc-the-most-efficient-texture-compression-standard-for-the-mobile-graphics-world
Taking texture compression to a new dimension with PVRTC2. January 2013. Available at: http://withimagination.imgtec.com/index.php/powervr/pvrtc2-taking-texture-compression-to-a-new-dimension
Beets Kristof. Understanding PowerVR Series5XT: PVRTC, PVRTC2 and texture compression. June 2013. Available at: http://withimagination.imgtec.com/index.php/powervr/understanding-powervr-series5xt-pvrtc-pvrtc2-and-texture-compression-part-6
Geldreich Rich. PVRTC Compression - First Experiments. Available at: https://sites.google.com/site/richgel99/early-pvrtc-compression-experiments
PVRTC Compression - First Coded 4bpp. PVR Texture. Available at: https://sites.google.com/site/richgel99/pvrtc-compression2
Nystad, Jorn, et al., et al., Adaptive Scalable Texture Compression. Eurographics Association. High Performance Graphics, 2012, pp. 105-114.
Ellis Sean and Nystad Jorn. ASTC Specification. 2012.
KHR_texture_compression_astc_hdr extension specification. 2013. Available at: http://www.opengl.org/registry/specs/KHR/texture_compression_astc_hdr.txt
ARM Launches Second Generation of MALI-T600 Graphics Processors Driving Improved User Experience for Tablets, Smartphones and Smart-TVs. 2012. Available at: http://www.arm.com/about/newsroom/arm-launches-second-generation-of-mali-t600-graphics-processors-driving-improved-user-experience.php
Lassen Jorn and Nystad Anders. Method of and apparatus for encoding and decoding data. UK Patent Application 2491689 GB, 2012.
Method of and apparatus for encoding and decoding data. UK Patent Application 2491448 GB, 2012.
Method of and apparatus for encoding and decoding data. UK Patent Application 2491687 GB, 2012.
Method of and apparatus for encoding and decoding data. UK Patent Application 2491688 GB, 2012.
Nystad Jorn Lassen, Anders and Olson, Tomas. Flexible Texture Compression Using Bounded Integer Sequence Encoding. New York, NY, USA : ACM, 2011. SIGGRAPH Asia 2011 Sketches. pp. 32:1–32:2.
Ellis Sean. ARM ASTC Texture Compression. CGDC (China Game Developers Conference), 2013.
Smith Stacy. ASTC does it. 2013. Available at: http://community.arm.com/groups/arm-mali-graphics/blog/2013/10/22/astc-does-it
Gustavson Stefan. Simplex noise demystified. 2005. Available at: http://www.itn.liu.se/~stegu/simplexnoise/simplexnoise.pdf
Ellis Sean. More ASTC in ARM Mali GPUs – High Dynamic Range and 3D. 2013. Available at: http://malideveloper.arm.com/engage-with-mali/more-astc-in-arm-mali-gpus-high-dynamic-range-and-3d/